这是我的 github 项目 https://github.com/shar-pen/GRPO_implementation_from_scratch.git 的讲解,在看之前,最好看下之前发的 GRPO&DAPO 的论文讲解。
数据准备 src/prepare_data.py 将推理任务和答案准备好,在 openai/gsm8k 数据集中 answer 字段的答案是长答案 + ### 后的短答案。在判断是否模型答对问题时,不会中间过程进行评估,而是对结果评估,因此实际只需要将短答案提取。
以下是 openai/gsm8k 的数据对示例:
1 2 3 4 5 6 7 Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? Answer: Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May. #### 72
以下是代码中的处理代码,我们将格式要求作为 system prompt,与问题构成对话。部分实现里会加入one shot QA 示例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 efault_system_prompt = """A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think>\n reasoning process here \n</think>\n<answer>\n answer here \n</answer>. """ def extract_final_answer (text ): if "####" not in text: return None return text.split("####" )[1 ].strip() def make_conversation (example, system_prompt=None ): prompt = [] if system_prompt is not None : prompt.append({"role" : "system" , "content" : system_prompt}) prompt.append({"role" : "user" , "content" : example['question' ]}) return {"prompt" : prompt, "solution" : extract_final_answer(example['answer' ])} dataset = load_dataset('openai/gsm8k' , 'main' , split='train' ) dataset_formatted = dataset.map ( partial( make_conversation, system_prompt=system_prompt, ), ) dataset_formatted = dataset_formatted.map ( partial(add_len, tokenizer=tokenizer), )
由于本项目是最低的实现,我对问题和答案长度进行了限制,希望模型不会遇到太复杂的问题而产生很长的 response。
1 2 3 4 5 6 7 8 9 10 11 12 13 def add_len (example, tokenizer ): prompt_ids = tokenizer.apply_chat_template(example["prompt" ], tokenize=True , add_generation_prompt=True ) answer_ids = tokenizer.encode(example["answer" ], add_special_tokens=False ) example["prompt_len" ] = len (prompt_ids) example["answer_len" ] = len (answer_ids) return example dataset_formatted = dataset_formatted.filter ( lambda x: x["prompt_len" ] <= 300 and x["answer_len" ] <= 200 , ) dataset_formatted = dataset_formatted.select(range (1024 ))
模型处理 src/model_utils.py 很短,仅有两个函数
优化模型设置: 修改设置,使显存占用降低
冻结模型: 参考模型需要冻结,以用于计算KL散度
1 2 3 4 5 6 7 8 9 def optimize_model_settings (model ): model.config.use_cache = False model.gradient_checkpointing_enable() def freeze_model (model ): model.eval () for param in model.parameters(): param.requires_grad = False
grpo相关util src/grpo_utils.py 有3个封装的函数,每个函数都有每个步骤的注释。
log prob 的计算函数
completion 的掩码
rollout 生成
grpo loss 计算
log prob 的计算就是正常 label shift 后,获取对应 label 的 log prob,注意不需要 sum,因为后面还需要加上 KL 散度。transformers 有这个函数,但我还是重写了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def get_per_token_log_probs ( model: AutoModelForCausalLM, input_ids: torch.Tensor, attention_mask: torch.Tensor, """ 计算每个 token 的 log-probability """ target_ids = input_ids[:, 1 :] logits = model(input_ids=input_ids, attention_mask=attention_mask).logits[:, :-1 , :] log_probs = torch.nn.functional.log_softmax(logits, dim=-1 ) per_token_log_probs = log_probs.gather(dim=-1 , index=target_ids.unsqueeze(-1 )).squeeze(-1 ) return per_token_log_probs
completion 的掩码,根据 eos_token_id 来获取 completion 的位置。这个函数参考了 grpo trainer 中同名函数的实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def create_completion_mask (completion_ids, eos_token_id ): """ 根据 completion_ids 创建 completion_mask,将 eos_token_id 之后置为 false """ is_eos = completion_ids == eos_token_id eos_idx = torch.full((is_eos.size(0 ),), is_eos.size(1 ), dtype=torch.long, device=completion_ids.device) mask_exists = is_eos.any (dim=1 ) eos_idx[mask_exists] = is_eos.int ().argmax(dim=1 )[mask_exists] sequence_indices = torch.arange(is_eos.size(1 ), device=completion_ids.device).expand(is_eos.size(0 ), -1 ) completion_mask = (sequence_indices <= eos_idx.unsqueeze(1 )).to(torch.int64) return completion_mask
rollout 生成,虽然 transformers 的 model.generate 函数不是很高效,grpo trainer 中也采用 vllm 来生成 rollout,但为了简易型我还是用了 model.generate,其实还跟 vllm 不支持 jupyter notebook 相关。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 @torch.no_grad() def generate_rollouts ( model: AutoModelForCausalLM, tokenizer: AutoTokenizer, prompts: list [list [dict [str , str ]]] | list [str ], num_of_roullout:int =8 , max_length: int = 1024 , temperature: float = 1.0 , top_p: float = 1.0 , top_k: int = 50 , ): model.eval () device = model.device if tokenizer.pad_token_id is None : tokenizer.pad_token_id = tokenizer.eos_token_id prompts = [ maybe_apply_chat_template(a_prompt, tokenizer) for a_prompt in prompts ] model_inputs = tokenizer( prompts, return_tensors="pt" , padding=True , padding_side="left" , return_attention_mask=True , ).to(device) model_inputs["input_ids" ] = model_inputs["input_ids" ].repeat_interleave(num_of_roullout, dim=0 ) model_inputs["attention_mask" ] = model_inputs["attention_mask" ].repeat_interleave(num_of_roullout, dim=0 ) prompt_length = model_inputs["input_ids" ].shape[1 ] generation_config = GenerationConfig( do_sample=True , top_p=top_p, top_k=top_k, temperature=temperature, max_length=max_length, pad_token_id=tokenizer.pad_token_id, ) sequence_ids = model.generate( **model_inputs, generation_config=generation_config ) completions = tokenizer.batch_decode( sequence_ids[:, prompt_length:], skip_special_tokens=True ) completion_mask = torch.zeros_like(sequence_ids, dtype=torch.int64) partial_completion_mask = create_completion_mask(sequence_ids[:, prompt_length:], tokenizer.eos_token_id) completion_mask[:, prompt_length:] = partial_completion_mask sequence_mask = torch.cat([model_inputs["attention_mask" ], partial_completion_mask], dim=1 ) return sequence_ids, sequence_mask, completion_mask, completions
grpo loss 计算,涉及 log prob ratio 的 clip,KL 散度的计算, completion mask 掩码计算 loss,和先样本内平均后样本间平均。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def get_grpo_loss ( model: AutoModelForCausalLM, sequence_ids: torch.Tensor, sequence_mask: torch.Tensor, completion_mask: torch.Tensor, advantage_per_sample: torch.Tensor, prob_per_token_old: torch.Tensor, prob_per_token_reference: torch.Tensor, epsilon: float , beta: float = 0.04 , prob_per_token_policy = get_per_token_log_probs( model, input_ids=sequence_ids, attention_mask=sequence_mask, ) coef_1 = (prob_per_token_policy - prob_per_token_old).exp() coef_2 = torch.clamp(coef_1, 1 - epsilon, 1 + epsilon) loss_per_token_1 = coef_1 * advantage_per_sample.unsqueeze(1 ) loss_per_token_2 = coef_2 * advantage_per_sample.unsqueeze(1 ) loss_per_token = -torch.min (loss_per_token_1, loss_per_token_2) kl_divergence_per_token = (prob_per_token_policy - prob_per_token_reference).exp() - (prob_per_token_policy - prob_per_token_reference) - 1 loss_per_token += beta * kl_divergence_per_token loss_per_completion = (loss_per_token * completion_mask[:, 1 :]).sum (dim=1 ) length_per_completion = completion_mask[:, 1 :].sum (dim=1 ).clamp(min =1 ) loss = (loss_per_completion / length_per_completion).mean() return loss
规则奖励函数 src/reward.py 包含若干规则和 grpo 的最内 advantage 计算函数
我使用了 format 奖励、xml tag奖励、准确率奖励
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 def extract_answer (text ): match = re.search(r'<answer>\n(.*?)\n</answer>' , text, re.DOTALL) if match : return match .group(1 ).strip() return None def format_reward (completion, **kwargs ): """ 检查预测文本是否符合特定格式要求。e.g., <think>\n...\n</think>\n<answer>\n...\n</answer> kwargs 参数可以用于传递额外的配置,但在此函数中未使用。 """ pattern = r"^<think>\n.*?\n</think>\n<answer>\n.*?\n</answer>$" if re.match (pattern, completion, re.DOTALL | re.MULTILINE): return 1.0 else : return 0.0 def tag_count_reward (completion, **kwargs ): """ 检查文本中 <think> 和 <answer> 标签的数量。 """ score = 0.0 if completion.count("<think>\n" ) == 1 : score += 0.25 if completion.count("\n</think>\n" ) == 1 : score += 0.25 if completion.count("\n<answer>\n" ) == 1 : score += 0.25 if completion.count("\n</answer>" ) == 1 : score += 0.25 return score def reasoning_steps_reward (completion, **kwargs ): pattern = r"(Step \d+:|^\d+\.|\n-|\n\*|First,|Second,|Next,|Finally,)" matches = re.findall(pattern, completion) score = min (1.0 , len (matches) / 3 ) return score def accuracy_reward (completion, solution, **kwargs ): """ 计算预测文本与真实答案之间的准确度奖励。 """ full_answer_content = extract_answer(completion) if full_answer_content is None : return 0.0 gold_parsed = parse(solution) answer_parsed = parse(full_answer_content) try : score = float (verify(gold_parsed, answer_parsed)) except Exception as e: print (f"verify failed: {e} , answer: {answer_parsed} , gold: {gold_parsed} " ) return 0.0 return score def compute_grpo_reward (completions, solutions, reward_funcs, reward_weights=None ): if reward_weights is None : reward_weights = [1.0 /len (reward_funcs)] * len (reward_funcs) assert len (reward_weights) == len (reward_funcs), "reward_weight and reward_funcs must have the same length" rewards_per_sample_per_func = torch.zeros(len (completions), len (reward_funcs)) for i, (a_completion, a_solution) in enumerate (zip (completions, solutions)): for j, reward_func in enumerate (reward_funcs): rewards_per_sample_per_func[i, j] = reward_func(a_completion, solution=a_solution) reward_weight_tensor = torch.tensor(reward_weights) reward_per_completion = (rewards_per_sample_per_func * reward_weight_tensor).sum (dim=1 ) reward_per_reward_func = rewards_per_sample_per_func.mean(dim=0 ) return reward_per_completion, reward_per_reward_func
grpo 组内 advantage 计算,注意组是指同一个问题内部计算 mean 和 std。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def compute_group_advantage (reward_per_sample: torch.Tensor, num_generations: int =None , eps: float = 1e-8 , scale_rewards: bool = True ): """ 基于 reward 计算 advantage """ if num_generations is None : num_generations = reward_per_sample.shape[0 ] mean_grouped_rewards = reward_per_sample.view(-1 , num_generations).mean(dim=1 ) std_grouped_rewards = reward_per_sample.view(-1 , num_generations).std(dim=1 ) mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(num_generations, dim=0 ) std_grouped_rewards = std_grouped_rewards.repeat_interleave(num_generations, dim=0 ) group_advantage = reward_per_sample - mean_grouped_rewards if scale_rewards: group_advantage /= (std_grouped_rewards + eps) return group_advantage
grpo 主函数 src/main_minibatch.py grpo 的主要流程分为:
rollout 生成
reward 计算
旧 policy model (当前 policy model)和参考 model 的 log prob 计算
grpo loss 计算并反向传播
rollout 生成 1 2 3 4 5 6 7 8 9 10 11 12 13 prompts = [example['prompt' ] for example in batch] solutions = [example['solution' ] for example in batch] sequence_ids, sequence_mask, completion_mask, completions = generate_rollouts( model_policy, tokenizer, prompts, num_of_roullout=n_roullout, max_length=max_length, temperature=1.0 , top_p=0.9 , top_k=50 , )
reward 计算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 reward_funcs = [format_reward, tag_count_reward, accuracy_reward] reward_weights = [0.5 , 0.5 , 1.0 ] solutions = [s for s in solutions for _ in range (n_roullout)] reward_per_completion, reward_per_reward_func = compute_grpo_reward( completions, solutions, reward_funcs, reward_weights, ) group_advantage_per_sample = compute_group_advantage( reward_per_completion ).to(device)
reward weight 最好倾向 accuracy_reward,其他格式相对好学习到。
旧 policy model 和参考 model 的 log prob 计算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 with torch.no_grad(): prob_per_token_old = [] prob_per_token_reference = [] for i in range (0 , len (sequence_ids), batch_size_micro_for_no_grad): sequence_ids_batch = sequence_ids[i:i + batch_size_micro_for_no_grad] sequence_mask_batch = sequence_mask[i:i + batch_size_micro_for_no_grad] prob_old_batch = get_per_token_log_probs( model_policy, input_ids=sequence_ids_batch, attention_mask=sequence_mask_batch, ) prob_ref_batch = get_per_token_log_probs( model_reference, input_ids=sequence_ids_batch, attention_mask=sequence_mask_batch, ) prob_per_token_old.append(prob_old_batch) prob_per_token_reference.append(prob_ref_batch) prob_per_token_old = torch.cat(prob_per_token_old, dim=0 ) prob_per_token_reference = torch.cat(prob_per_token_reference, dim=0 )
计算这里用了 torch.no_grad(),但 rollout 太多了还是会超显存,因此这里还是采用 mini batch
grpo loss 计算并反向传播 这里 FWD 和 BWD 都采用了 mini batch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 for _ in range (mu): optimizer.zero_grad() for i in range (0 , len (sequence_ids), batch_size_micro): sequence_ids_batch = sequence_ids[i:i + batch_size_micro] sequence_mask_batch = sequence_mask[i:i + batch_size_micro] completion_mask_batch = completion_mask[i:i + batch_size_micro] group_advantage_per_sample_batch = group_advantage_per_sample[i:i + batch_size_micro] prob_per_token_old_batch = prob_per_token_old[i:i + batch_size_micro] prob_per_token_reference_batch = prob_per_token_reference[i:i + batch_size_micro] loss = get_grpo_loss( model_policy, sequence_ids_batch, sequence_mask_batch, completion_mask_batch, group_advantage_per_sample_batch, prob_per_token_old_batch, prob_per_token_reference_batch, epsilon, beta ) loss.backward() optimizer.step()
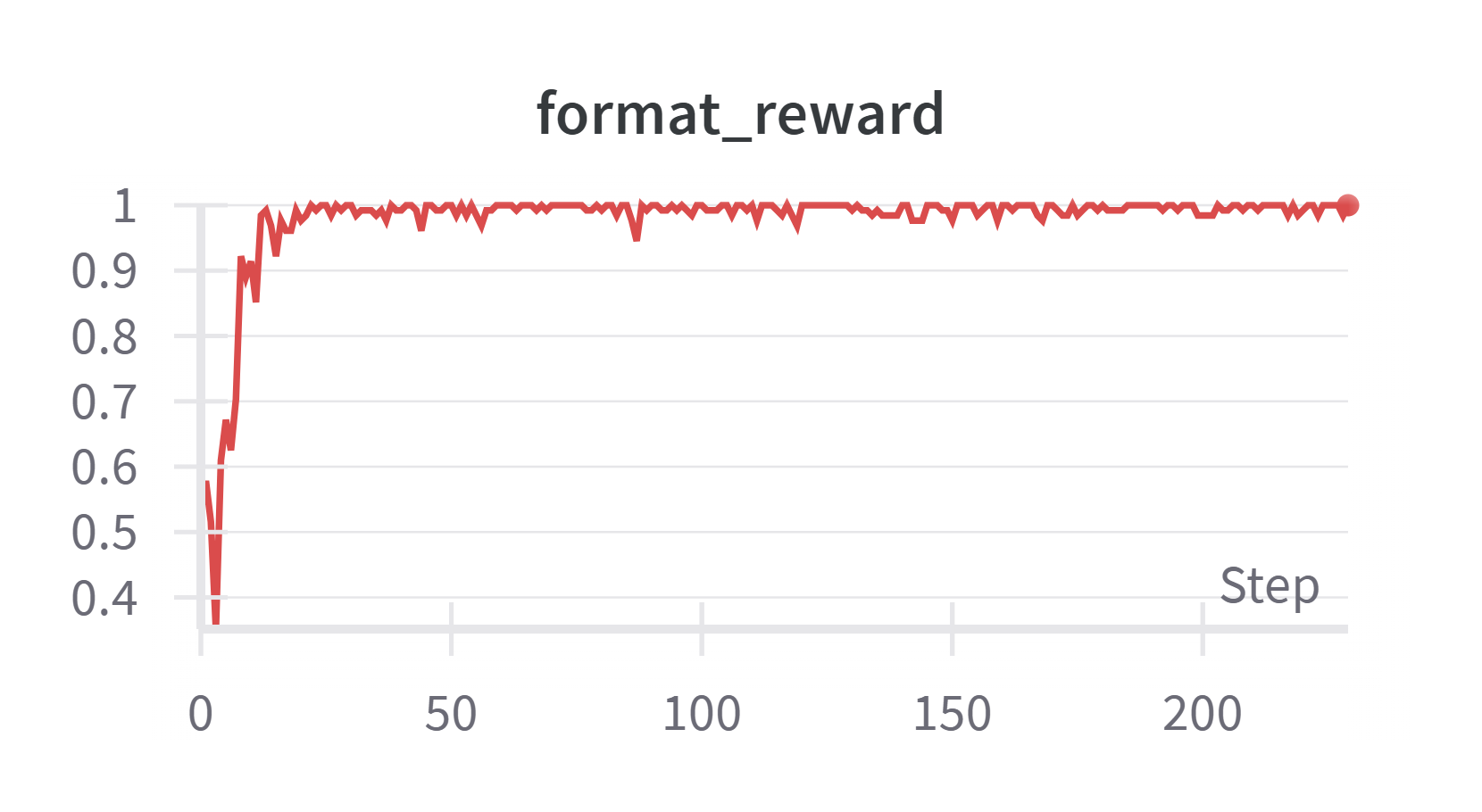
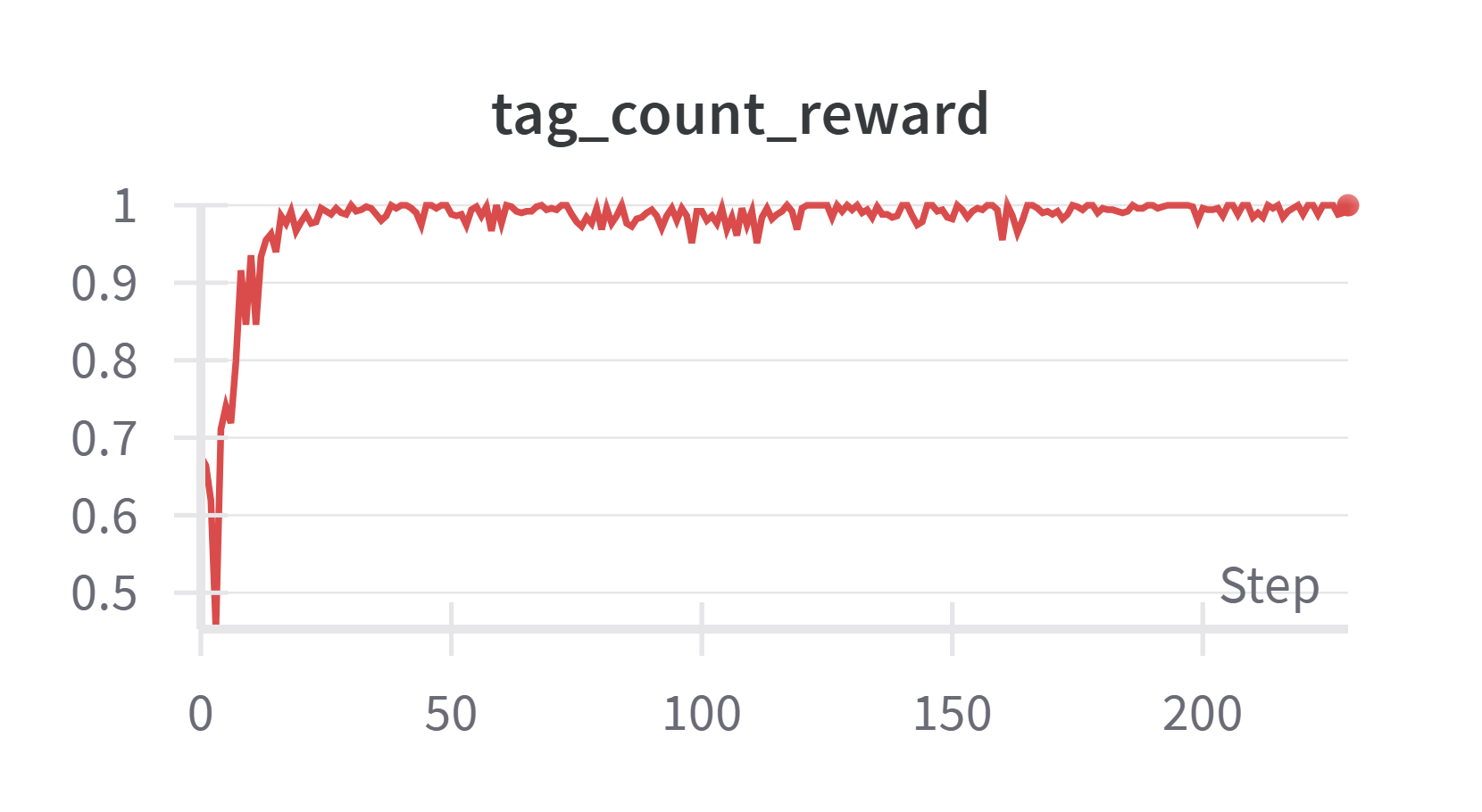
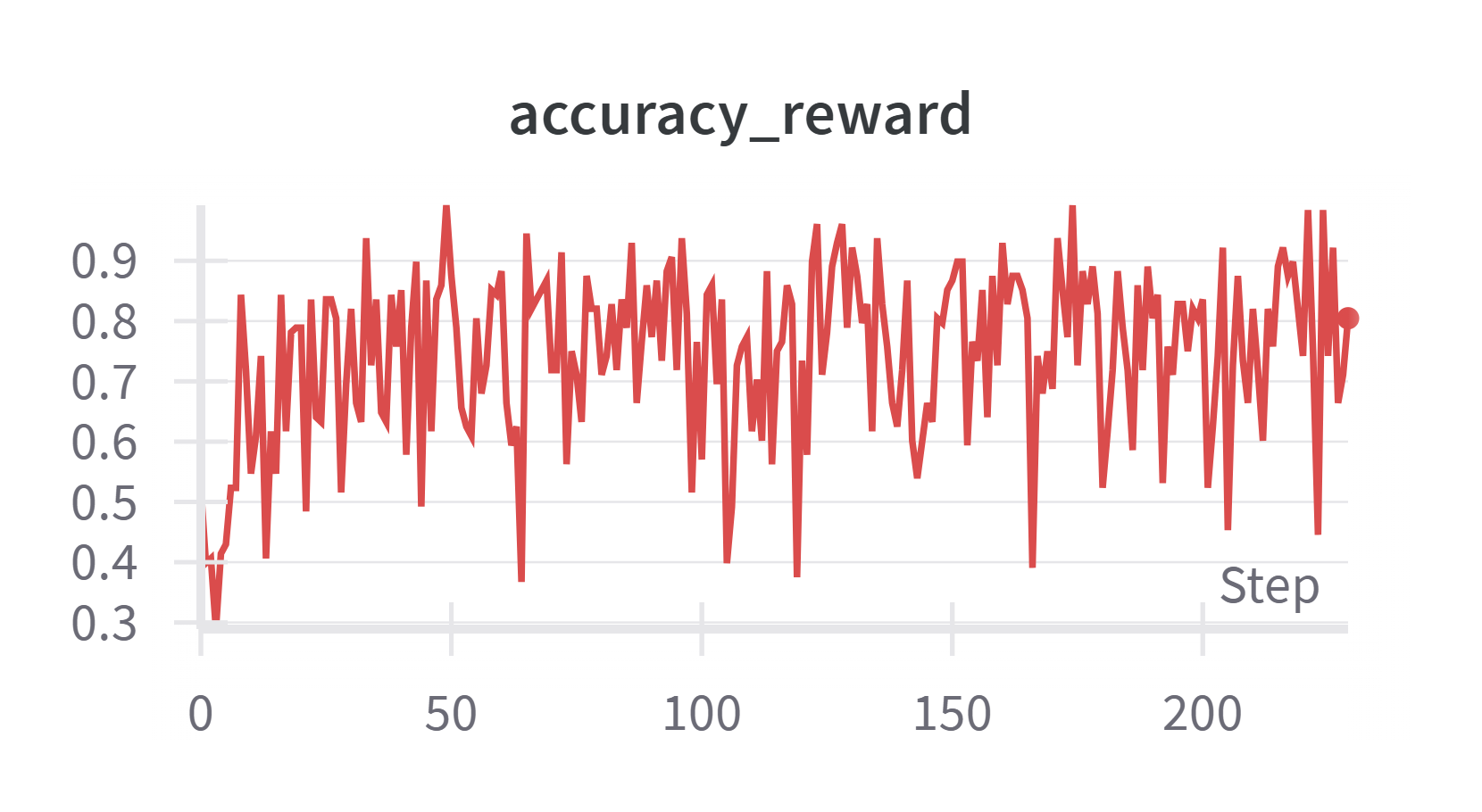
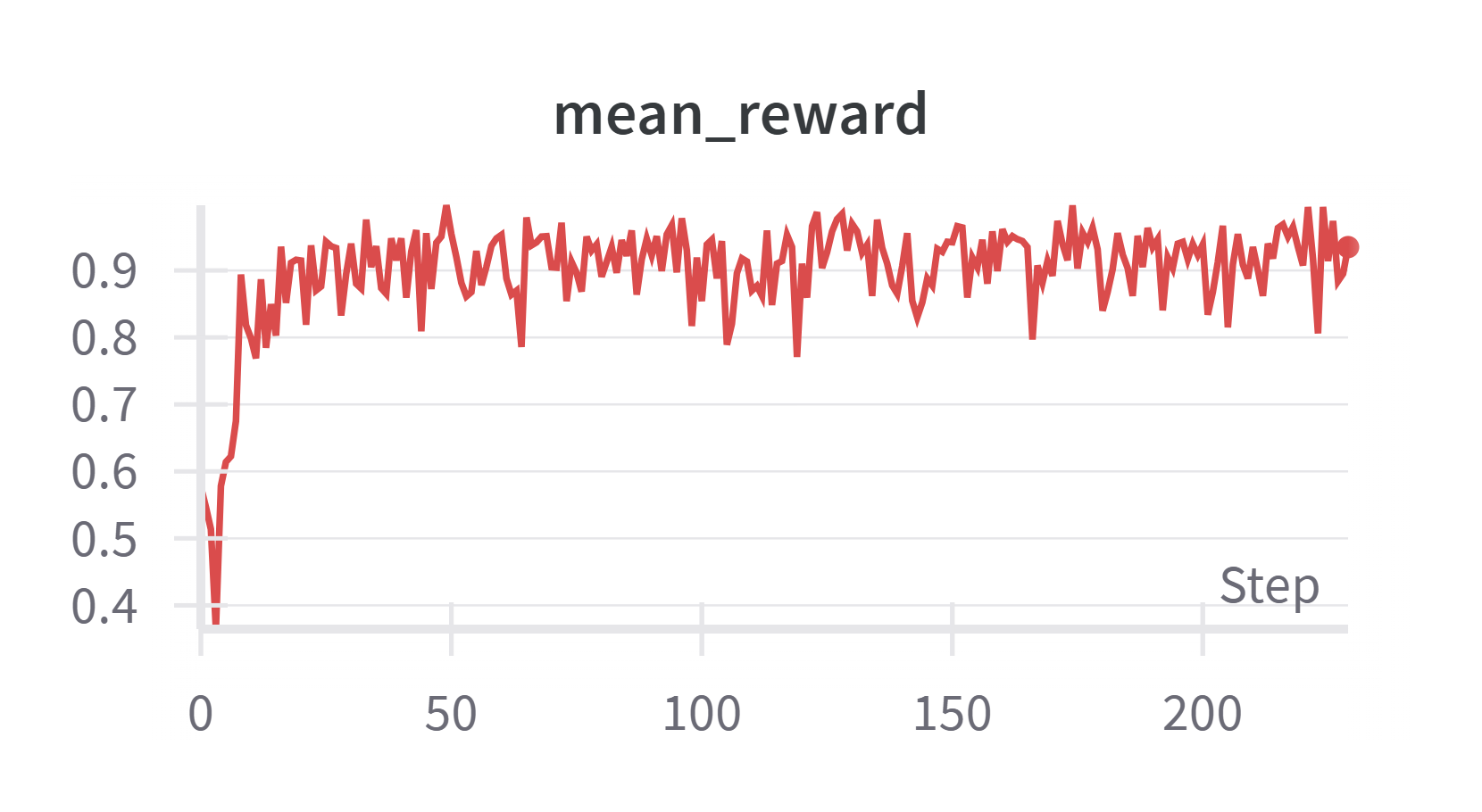
GRPO 结果
整体 reward 曲线算正常。tag 和 format 很快学习到,accuracy 比较难学,且波动也很大。