
GRPO & DAPO 论文解读
GRPO 起源于 DeepSeekMath, 是一种高效且有效的强化学习算法。GRPO的核心思想是通过组内相对奖励来估计基线(baseline),从而避免使用额外的价值函数模型(critic model)与 PPO 相比,显着减少了训练资源 (PS: 他不需要 actor-critic网路,两个与训练模型相当的模型)。传统的PPO算法需要训练一个价值函数来估计优势函数(advantage function),而GRPO通过从同一问题的多个输出中计算平均奖励来替代这一过程,显著减少了内存和计算资源的消耗。
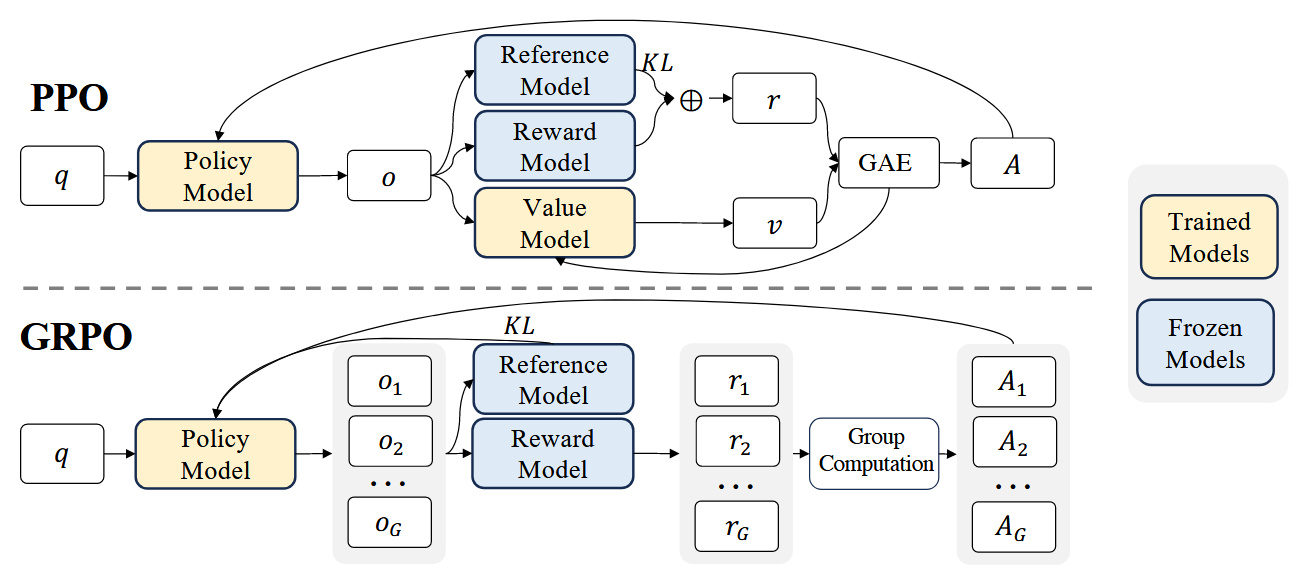
从图上可以看出,GRPO 与PPO 的主要区别有:
- GRPO 省略了 value function model 和 reward model.
- GRPO reward 计算,改成了一个问题 q 生成多个回答 r, 然后基于 reward function打分。
- PPO 优势函数计算时,KL 是包含在GAE内部的。 GRPO 直接挪到了外面,同时修改了计算方法。
PPO
其中:
是当前策略与旧策略的比值,注意 r 代表 ratio 而不是 reward; 是估计出的优势函数(Advantage),表示当前动作相对平均策略的好坏; 是超参数,控制允许的策略变动范围(如 0.2); clip操作将限制在 ; - 取
min是为了在超过 clip 区间时使用“惩罚值”,防止过度优化。
clip 对梯度更新的影响是
| Advantage 符号 |
原始项 |
clip项 |
实际值 = min(…) | 是否发生clip限制 | |
|---|---|---|---|---|---|
| N | |||||
| N | |||||
| Y | |||||
| Y | |||||
| N | |||||
| N |
目标是抑制策略比例变化
- 如果 Advantage 是正的(动作好),希望增加概率,但 clip 会限制其比例最多增加到
。 - 如果 Advantage 是负的(动作差),希望减少概率,但 clip 会限制其比例最多减少到
。
注意这点,DAPO 会在这里改进。
这是典型的 PPO (Proximal Policy Optimization) 损失函数,用于强化学习中策略更新的稳定性,特别是在文本生成任务如RLHF或GRPO中。其中
GRPO
objective
与 PPO 相比,GRPO 消除了价值函数,并以群体相对方式估计优势。对于特定的问题-答案对 (q, a),行为策略
与 PPO 类似,GRPO在原始目标的基础上加上了 KL 散度惩罚项 (**限制当前策略与参考策略之间的差异,不让策略变化太激进。**PPO是在 reward 里加入KL 重复项,GRPO reward 计算不同,因此直接额外加入 KL 项)
从图片中提取的公式如下:
:问题-答案对来自数据集。 :从旧策略 生成的 个候选输出(rollouts)。 :第 个输出的 token 长度。
值得注意的是,GRPO 在 sample-level 样本级别计算目标。具体来说,GRPO 首先 sample 内 loss先平均化,再 sample 间 loss 平均化。这一点在 DAPO 里会改变。
算法流程

对于每一批数据
- 先更新
- 用
为每个问题产生 个 rollout - 用 reward model/function 计算每条 rollout
的奖励 - 用组内优化估计(归一化)的方式计算
(或者 ,GRPO reward/adavantage 都是 sample-level的,同一 sample 内每个token都一样) - 迭代用 GRPO loss 更新
以下是 DeepseekMath 中提及的超参:
| 超参数名称 | 说明 | 论文中设置值 |
|---|---|---|
| 𝜀(epsilon) | clip 参数,控制概率比的上下界以防止过大更新 | 0.2 |
| 𝛽(beta) | KL 正则项系数,用于防止 policy 偏离 reference 过远 | 0.04 |
| 𝜇(mu) | 每次 rollout 后对该 batch 执行的 GRPO 训练迭代次数 | 1 |
| G(group size) | 每个问题采样的回答数量,用于计算 group 平均奖励作为 baseline | 64 |
| Max Length | 每个回答的最大 token 长度 | 1024 |
| Training Batch Size | 每次训练的 batch 大小(总生成样本数) | 1024 |
| Policy LR | Policy 模型的学习率 | 1e-6 |
| Reward LR | 奖励模型的学习率 | 2e-5 |
reward
reward 包括 rule-based reward 和 reward model,前者完全基于规则,后者基于大模型作为评估模型,模拟人类偏好。DeepseekMath page 20 交代了奖励的设置,
The algorithm processes the reward signal to the gradient coefficient to update the model parameter.
We divide the reward function as ‘Rule’ and ‘Model’ in our experiments.
- Rule refers to judging the quality of a response based on the correctness of the answer
- Model denotes that we train a reward model to score each response.
The training data of the reward model is based on the rule judgment.
Deepseek r1-zero使用了规则奖励 (同时因为只有可通过规则评估的数据):
- Accuracy rewards: The accuracy reward model evaluates whether the response is correct. 结果的准确性奖励
- Format rewards: In addition to the accuracy reward model, we employ a format reward model that enforces the model to put its thinking process between ‘
’ and ‘ ’ tags. 格式奖励,主要是 tag。
他们试过过程奖励,但效果不行,容易 reward hacking,且维护 reward model 需要额外计算资源,因此放弃了。
Deepseek r1 扩充了额外数据,其中使用生成式的 reward model 来评估 (同时给 ground-truth 和 prediction)。Deepseek R1 page 11 说明了 reward model 是基于 deepseek v3 和偏好数据训练出来的,评估维度为 helpfulness 和 harmlessness。
Specifically, we train the model using a combination of reward signals and diverse prompt distributions.
- For reasoning data, we adhere to the methodology outlined in DeepSeek-R1-Zero, which utilizes rule-based rewards to guide the learning process in math, code, and logical reasoning domains.
- For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios.
We build upon the DeepSeek-V3 pipeline and adopt a similar distribution of preference pairs and training prompts.
- For helpfulness, we focus exclusively on the final summary, ensuring that the assessment emphasizes the utility and relevance of the response to the user while minimizing interference with the underlying reasoning process.
- For harmlessness, we evaluate the entire response of the model, including both the reasoning process and the summary, to identify and mitigate any potential risks, biases, or harmful content that may arise during the generation process.
Ultimately, the integration of reward signals and diverse data distributions enables us to train a model that excels in reasoning while prioritizing helpfulness and harmlessness.
同时,deepseek-r1 zero 训练时出现语言混乱的情况,为了解决这点,deepseek-r1 加入了语言一致性 reward,基于 CoT 中目标语言的比例计算。虽然这回导致模型性能会少量降低,但和人类偏好更对齐。
DAPO
DAPO 相比于 GRPO 先改了两方面,不算大的修改:
- 删除 KL 散度: 在训练长思维链推理模型时,模型分布可能与初始模型显著偏离,因此这种限制不是必要的。因此,DAPO将从我们提出的算法中排除 KL 项。
- 规则奖励: 奖励模型可能会出现 reward hacking,所以它直接用结果的准确率作为输出奖励。
较大的修改有 4 项:
- Clip-Higher:将 clip 的上限
- Dynamic Sampling
- Token-Level Policy Gradient Loss
- Overlong Reward Shaping
DAPO(Dynamic Advantage-weighted Policy Optimization) 的损失函数表达形式为

Clip-higher
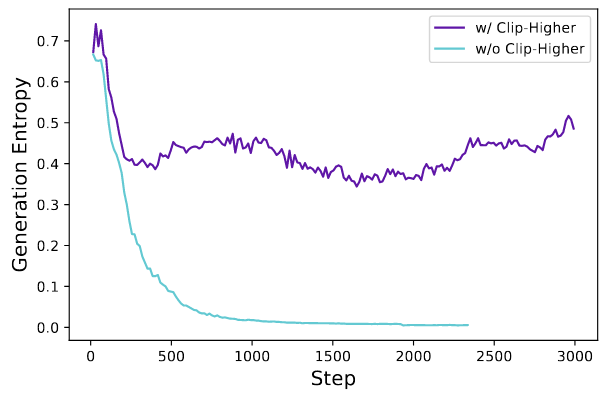
熵崩现象:策略的熵随着训练的进行而迅速下降,采样回答都同质化,这就会导致探索是低效的。这主要是由于在对称 clip([1−ε,1+ε])里,低概率但有正优势的 token(潜在高质量探索)被上界强压,涨幅很有限;高概率且有正优势的 token 提升相对更容易、绝对增量更大,分布会更快向少数高概率模式集中;多步迭代后,采样更偏向这些高概率模式,熵(多样性)下降。熵崩描述的是分布变窄(模式坍缩),它可能偏向“高概率且能拿到正回报的套路”,这些套路有时是高质量,但也可能是保守/模板化、在多样化任务上并非最优的模式。换句话说:质量未必持续提高,但多样性一定在降。
Clip-Higher 是把 PPO/GRPO 的对称截断区间
以一般的参数值
- 若旧概率很小(探索向 token,如 0.01),上界只允许涨到
,几乎涨不动; - 若旧概率很大(开发 token,如 0.9),实际上能“无感地”继续逼近 0.999(虽然比值被 1.2 限住,但绝对概率仍可很大)。
这导致探索受限、熵快速塌缩。
Clip-Higher 针对这个问题:抬高上界
Dynamic Sampling
现有的RL算法在某些提示的准确率等于1时存在梯度递减问题。在每个问题
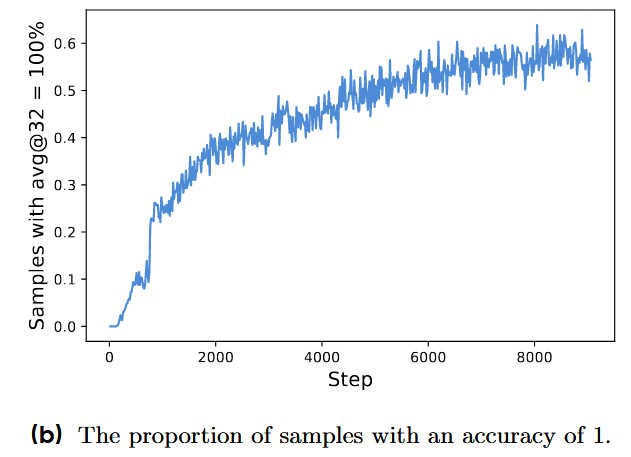
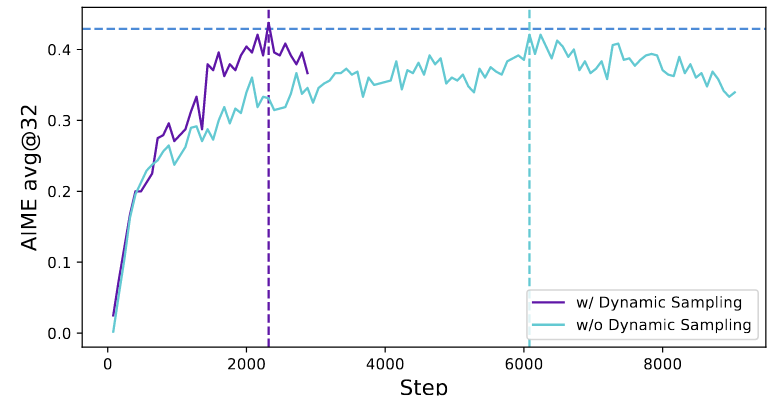
动态采样 过采样并过滤准确率为 1 和 0 的组,只留下有有效梯度的组,同时维持 batch里有效组数稳定。采样开销因此会动态变化,但整体收敛更快(步数更少),训练时间基本不受影响,事实上会更快达到目标。
Token-Level Policy Gradient Loss
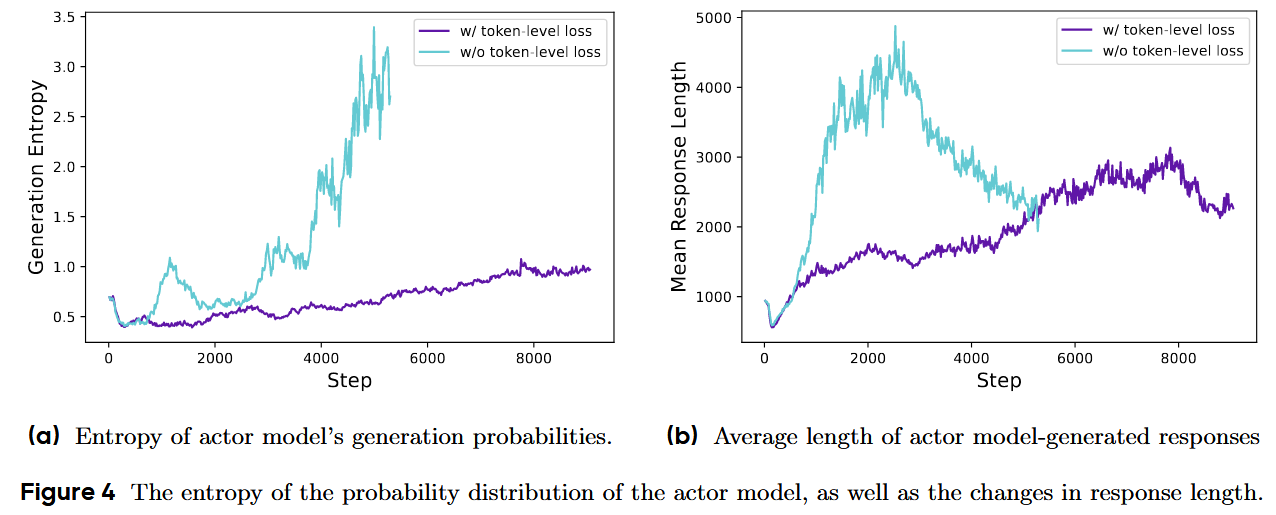
传统 GRPO 的做法是先在每个样本内按 token 平均(把一条回复的 token 损失取均值),再跨样本再平均,因此每条样本权重相同。导致两个问题:
- 长但高质的推理被弱化——因为一条长样本被“先平均”后,其包含的关键 token 信号被摊薄;
- 过长且低质(重复/胡言)惩罚不够——无法对这些不良模式施加足够的负梯度,导致熵和长度出现不健康增长。
DAPO 改为直接在 token 级别聚合:把所有样本的所有 token 放到同一个求和里,再按总 token 数归一;这样长序列贡献更多 token 权重,而不是被“每样本等权”稀释。论文明确指出 GRPO 的“样本级”做法及其影响,并引出 token-level 方案。Token-level 聚合的直观好处是,长序列按 token 占更多比重;任何“会提高/降低回报的生成模式”,不受序列长度影响而得到相应强化或抑制。
$$
J_{\text{DAPO}}(\theta)=\mathbb{E} \Bigg[
\frac{1}{\sum_{i=1}^{G}\lvert o_i\rvert}
\sum_{i=1}^{G}\sum_{t=1}^{\lvert o_i\rvert}
\min\big(
r_{i,t}(\theta),\hat A_{i,t},;\text{clip}(r_{i,t}(\theta),1-\varepsilon_{\text{low}},1+\varepsilon_{\text{high}}),\hat A_{i,t}
\big)\Bigg],
\
\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E} \Bigg[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \Big( \min \big( r_{i,t}(\theta) \hat{A}_{i,t}, , \text{clip}( r_{i,t}(\theta), 1-\varepsilon, 1+\varepsilon ) \hat{A}_{i,t} \big) - \beta D_{\mathrm{KL}}(\pi_\theta | \pi_{\text{ref}}) \Big) \Bigg].
$$
注意 DAPO 中 sum 的方式和 GRPO 不一样了。
Overlong Reward Shaping
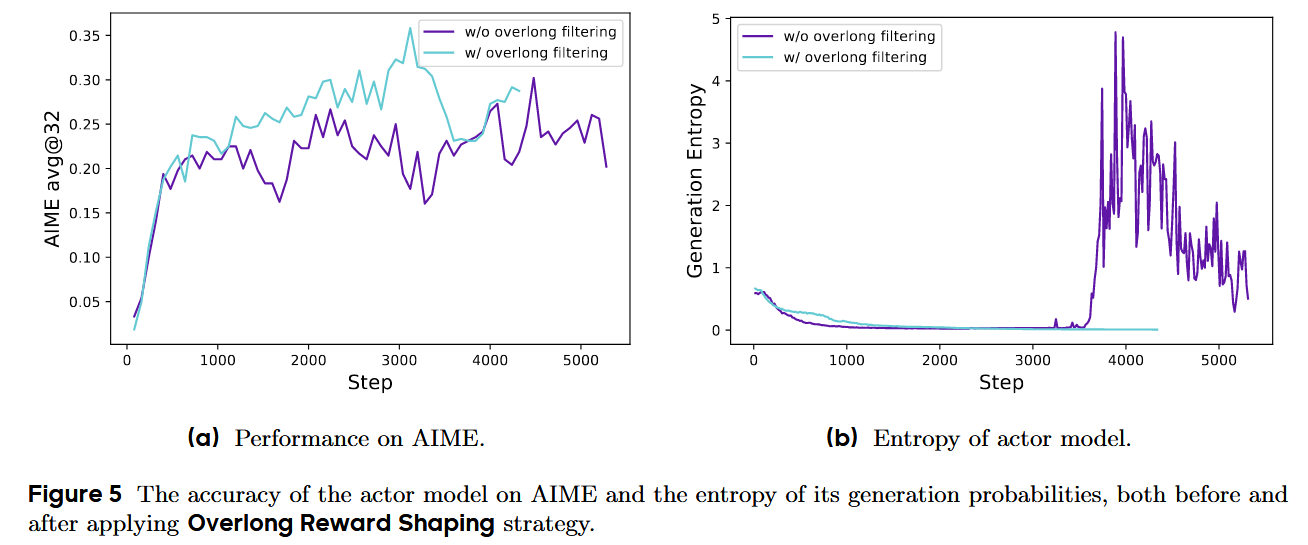
在长链路推理(long-CoT)RL 中,训练通常会设置最大生成长度,超过上限的输出会被截断。作者发现:对这些被截断样本做不当的奖励处理会带来“奖励噪声”,显著干扰训练。默认做法常对“被截断的样本”一律给负奖惩。这会把“本来推理正确、只是写太长”的样本也惩罚掉,等价于引入奖励噪声,从而误导策略更新。但这种数据其实也不好处理,因为它本身不完整,因此不好评估,作者的解决方法也是不评估,直接过滤。
Overlong Filtering:对被截断的样本,直接屏蔽其损失(不参与反传),先把噪声从优化里拿掉;实验显示这能显著稳定训练并提升效果。
此外,DAPO增加了一个软长度惩罚 Soft Overlong Punishment,用于惩罚超长以及那些接近超长的序列。论文设置
当
时,不加惩罚(0); 当
时,线性惩罚从 0 逐步加到 −1; 当
时,惩罚为 −1。 该惩罚与原有的对/错规则奖励相加作为总奖励。
训练结果
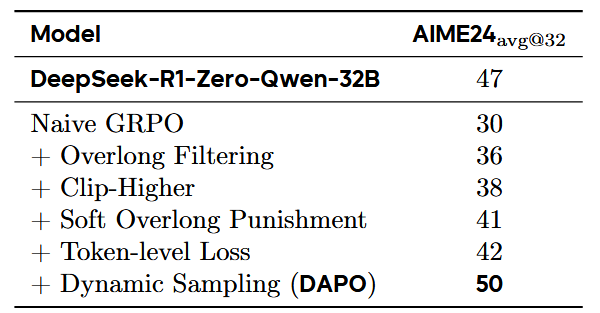
从表格里看,最大贡献的是 dynamic sampling 提升了8,其次是 overlong filtering 提升了6,其他项的提示再1-3间。