
LLM 推理 & speculative sampling
推理基本方式
贪心解码
类似于分类器通常会选择概率最大的标签,对于文本生成任务,最直接的方法就是每次取概率最大的token_id,接下来我以贪心搜索为例介绍文本生成的流程。
1 | # Encode initial input |
1 | # encode context the generation is conditioned on |
LLM的 logit 是 batch size * seq length * token num,在训练时,模型通常是用第 i-1 位的 logit 去预测第 i 位的 token id,所以预测时用最后一位的 logit 去预测新的 token id,结果softrmax后,我们得到新的 token id,然后按照 auto regressive 的风格,把新 token id加入到 之前的 token id 序列中, 再用相同的方法得到下一个 token id。这就是预测的整体流程, 贪心搜索只不过决定了新的 token id 的选择。

以图中的概率发布,解码结果位 ‘The cat is’。
在给定上下文生成的词语是合理的,但模型很快开始重复自己!这是语言生成中一个非常常见的问题,尤其在贪婪搜索和波束搜索中更为明显。然而,贪婪搜索的主要缺点是它会错过那些被低概率词遮挡的高概率词。其实是因为它的视野窗口只有1,因此无法做出偏长远的判断。
top-k采样
在 top-k采样中,模型会筛选出 k 个最可能的下一 token,并将概率质量重新分配到这 K 个token,然后在他们之中随机采样。
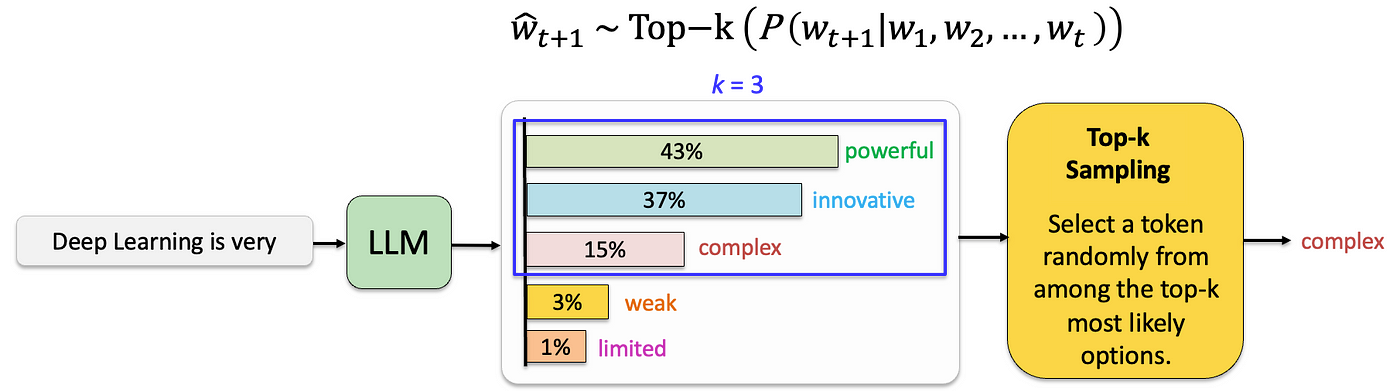
计算token概率:在模型处理输入文本后,它会预测可能的下一个 token 的概率分布。
筛选 top-k:与考虑所有可能的 token 不同,top-k 采样将选择范围缩小到概率最高的 k 个 token 。这种“剪枝”减少了潜在输出空间,专注于最可能的下一 token ,而忽略了不太可能的选项。
随机采样:从 top-k token 中,重新分配他们的概率(一般再除以概率和,使得整体概率和仍对于1),根据它们的概率随机采样一个 token ,而不是总是选择最高概率的词元。这种方式引入了多样性,使生成的文本更加丰富多样。
1 | topk_output = model.generate(**model_inputs, |
通过调整 k 的值,高 k 值(例如 50 或 100)允许更多的选择,增加了多样性和创造性,但可能降低连贯性。低 k 值(例如 5 或 10)限制了选项,通常使文本更具确定性和集中性,但有时也会导致内容过于重复或保守。

然而,top-k采样的一个问题是,它不会动态调整从下一个 token 的概率分布中过滤的 token 。这可能会导致问题,因为某些 token 可能来自非常陡峭的分布(即集中于少数词的分布,这时更容易加入很低概率的 token ,保留他们的意义不大),而其他词则来自更平坦的分(这种情况 token 的选择更正常)。例如图中左侧发布相对平坦,概率更均匀, top-6 随机采样时合理的,右侧发布主要集中在 top-3 中,如果取 top-6,后三个词的概率太小了,往往不可能选中,因此这样的概率在一开始就不需要成为候选。
因此,将采样池限制为固定大小 k 可能会导致模型在陡峭分布中产生无意义的内容,而在平坦分布中限制模型的创造力。
top-p采样
与仅从最可能的 k 个 token 中采样不同,top-p 采样选择的是累计概率超过阈值 p 的最小 token 集合。
它与 top-k 的区别仅在于筛选方式。top-k 采样选择个体概率最高的前 k 个 token ,而 top-p 采样则考虑累计概率至少为 p 的最小 token 集合,即概率较大的那些 token 。
1 | topp_output = model.generate(**model_inputs, |
在开放式语言生成中,top-p 和 top-k 采样似乎比传统的贪心搜索和 beam search 生成更流畅的文本。但有人证明,贪心搜索和 beam search 的明显缺陷(主要是生成重复词序列)是由模型本身(尤其是模型的训练方式)引起的,而不是生成方法的问题。
temperature
采样方法过程中都涉及到对部分数据采样,但通常都会把他们原始的概率进行调整。概率调整时的重要参数就是 temperature,它在文本生成中用于控制生成内容的随机性或创造性。通过调整可能生成的下一个 token 的概率分布,temperature 参数可以让模型生成的文本更保守或更具有创意。
temperature 会对每个可能生成的下一个 token 的概率分布进行缩放。temperature 越高,分布越“平”,即模型对每个候选 token 的选择倾向性降低,更可能从更大范围的 token 中随机选取下一个 token 。temperature 越低,分布越“尖”,模型会更偏向选择高概率的候选 token ,这样生成的文本就会更可预测和连贯。
speculative sampling
speculative sampling 基本思想时利用小模型先自回归生成,然后大模型批量评估,如果接受则继续生成,如果不接受,利用大模型评估的结果重新计算对应位置的token。

步骤如下:
- draft model
基于 prefix 逐个生成 ,其中 是小模型生成的长度,同时也要返回对于位置的分布概率 - 用 target model
基于 为 input_ids 生成对应位置的发布概率 - 对于每个位置,以 target model 的 token 概率与 draft model 的 token 概率为接受率
,取一个随机数,如果随机了大于此概率则接受,这个位置的 token 就是 ,否则就是不接受,那这个位置的 token 就直接基于 来推理,之后的 token 就没法推理了,因为此后 target model 的发布概率是基于不被接受的 token 产生的。 - 如果所有 token 都被接受,那可以利用 target model 产生的最后一位的发布概况,直接推理出新的token

原论文有半页内容解释为什么这样子推理的概率发布等同于 target model 的概率发布,很简单,不解释了。
至于为什么快了,因为推理的时间成本在于自回归的解码,只有先生成上一个位置的 token,才能把 token 加入然后生成新的 token。模型越大,生成每一个 token 的时间越长。speculative sampling 就是让小模型先生成,再大模型验证,而且大模型的发布概率是不需要一次一次计算的,是基于一段新的token 批量计算的,因此会快。
但 speculative sampling 不能与 top k 和 top p 共同设置,因为接受率
代码实现
1 | import os |
huggingface model generate 函数
正常推理可以直接用 model.generate 函数
1 | text = 'Do not go gentle into that good night,\nOld age should burn and rave at close of day;' |
1 | Do not go gentle into that good night, |
naive 贪心解码 (带kv cache)
在调用 model.forward(input_ids=input_ids, past_key_values=past_kv) 时:input_ids 中应该只包含“新输入的 token”,也就是**还未被缓存(未进入 past_key_values)**的 token。
1 | def autoregressive_generate_by_greedy_search( |
1 | 100%|██████████| 20/20 [00:00<00:00, 26.17it/s] |
naive top k & top p & temperature 解码 (带 kv cache)
1 | def apply_top_k_filter(probs: torch.Tensor, top_k: int = 0): |
1 | def autoregressive_generate_by_sampling( |
1 | 100%|██████████| 20/20 [00:00<00:00, 30.06it/s] |
speculative sampling
1 | target_model = AutoModelForCausalLM.from_pretrained( |
1 | def truncate_kv_cache(past_key_values, new_length): |
1 | Accepted 1 tokens. Total length: 23 |