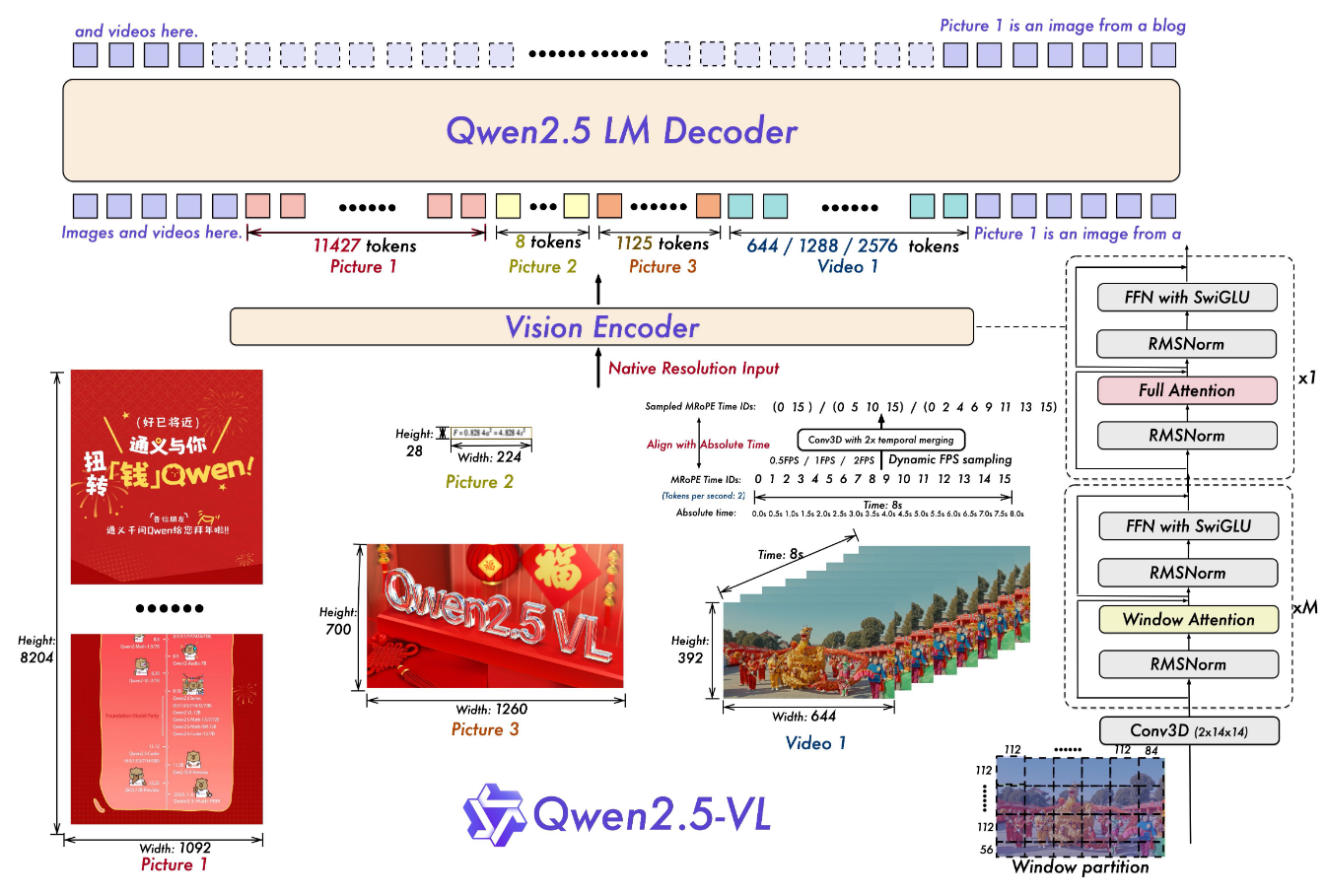
QWEN2.5-VL框架展示了视觉编码器和语言模型解码器的集成,以处理多模式输入,包括图像和视频。视觉编码器旨在以其本机分辨率处理输入,并支持动态FPS采样。具有不同FPS速率的不同尺寸和视频帧的图像被动态映射到长度不同的token。
加载模型 1 2 3 4 5 6 7 8 9 10 11 12 13 import torchfrom qwen_vl_utils import process_vision_infofrom transformers import Qwen2_5_VLForConditionalGeneration, Qwen2_5_VLProcessormodel_name_or_path = "../DC/Qwen2.5-VL-3B-Instruct" model = Qwen2_5_VLForConditionalGeneration.from_pretrained( model_name_or_path, torch_dtype="auto" , device_map="cuda:5" , ) processor = Qwen2_5_VLProcessor.from_pretrained(model_name_or_path)
推理完整流程 接下来会一一讲解推理处理流程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 messages = [ { "role" : "user" , "content" : [ { "type" : "image" , "image" : "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg" , }, {"type" : "text" , "text" : "Describe this image." }, ], } ] text = processor.apply_chat_template( messages, tokenize=False , add_generation_prompt=True ) image_inputs, video_inputs = process_vision_info(messages) inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True , return_tensors="pt" , ) inputs = inputs.to(model.device) generated_ids = model.generate(**inputs, max_new_tokens=128 ) generated_ids_trimmed = [ out_ids[len (in_ids) :] for in_ids, out_ids in zip (inputs.input_ids, generated_ids) ] output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True , clean_up_tokenization_spaces=False ) print (output_text)
Qwen2_5_VL 的模型组成如下: Qwen2_5_VisionTransformerPretrainedModel(vision encoder)和 Qwen2_5_VLModel(LM decoder)。vision encoder 还是 ViT, patch embedding 由卷积层实现, 旋转位置编码, 之后就是正常 transformer Block 的叠加, 最后 merger 就是将 vision embedding 投影到 text modal 的 projecter, qwen2.5 vl 用的只是两层 MLP, 注意下 shape, 明显 block 的输出是 1280, merger.mlp 的输入是 5120, 这是因为将相邻的 2*2 个 token 进行融合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 Qwen2_5_ VLForConditionalGeneration( (visual): Qwen2_5_ VisionTransformerPretrainedModel( (patch_embed): Qwen2_5_VisionPatchEmbed( (proj): Conv3d(3, 1280, kernel_size=(2, 14, 14), stride=(2, 14, 14), bias=False) ) (rotary_pos_emb): Qwen2_5_VisionRotaryEmbedding() (blocks): ModuleList( (0-31): 32 x Qwen2_5_VLVisionBlock( (norm1): Qwen2RMSNorm((1280,), eps=1e-06) (norm2): Qwen2RMSNorm((1280,), eps=1e-06) (attn): Qwen2_5_VLVisionSdpaAttention( (qkv): Linear(in_features=1280, out_features=3840, bias=True) (proj): Linear(in_features=1280, out_features=1280, bias=True) ) (mlp): Qwen2_5_VLMLP( (gate_proj): Linear(in_features=1280, out_features=3420, bias=True) (up_proj): Linear(in_features=1280, out_features=3420, bias=True) (down_proj): Linear(in_features=3420, out_features=1280, bias=True) (act_fn): SiLU() ) ) ) (merger): Qwen2_5_VLPatchMerger( (ln_q): Qwen2RMSNorm((1280,), eps=1e-06) (mlp): Sequential( (0): Linear(in_features=5120, out_features=5120, bias=True) (1): GELU(approximate='none') (2): Linear(in_features=5120, out_features=2048, bias=True) ) ) ) (model): Qwen2_5_VLModel( (embed_tokens): Embedding(151936, 2048) (layers): ModuleList( (0-35): 36 x Qwen2_5_VLDecoderLayer( (self_attn): Qwen2_5_VLSdpaAttention( (q_proj): Linear(in_features=2048, out_features=2048, bias=True) (k_proj): Linear(in_features=2048, out_features=256, bias=True) (v_proj): Linear(in_features=2048, out_features=256, bias=True) (o_proj): Linear(in_features=2048, out_features=2048, bias=False) (rotary_emb): Qwen2_5_VLRotaryEmbedding() ) (mlp): Qwen2MLP( (gate_proj): Linear(in_features=2048, out_features=11008, bias=False) (up_proj): Linear(in_features=2048, out_features=11008, bias=False) (down_proj): Linear(in_features=11008, out_features=2048, bias=False) (act_fn): SiLU() ) (input_layernorm): Qwen2RMSNorm((2048,), eps=1e-06) (post_attention_layernorm): Qwen2RMSNorm((2048,), eps=1e-06) ) ) (norm): Qwen2RMSNorm((2048,), eps=1e-06) (rotary_emb): Qwen2_5_VLRotaryEmbedding() ) (lm_head): Linear(in_features=2048, out_features=151936, bias=False) )
预处理 message 文本预处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 messages = [ { "role" : "user" , "content" : [ { "type" : "image" , "image" : "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg" , }, {"type" : "text" , "text" : "Describe this image." }, ], } ] text = processor.apply_chat_template( messages, tokenize=False , add_generation_prompt=True ) print (text)
1 2 3 4 5 <|im_start|>system You are a helpful assistant.<|im_ end|><|im_start|>user <|vision_ start|><|image_pad|><|vision_ end|>Describe this image.<|im_end|> <|im_ start|>assistant
输入文本被处理成对话模板的样式,图片或者视频暂时被 <|image_pad|> 这样的占位符替代。
图片 resize 1 2 3 image_inputs, video_inputs = process_vision_info(messages) image_inputs
内部执行 fetch_image() 和 fetch_video() 函数获取图片和视频,期间还会执行 resize
1 2 3 4 5 6 7 8 resized_height, resized_width = smart_resize( height, width, factor=size_factor, min_pixels=min_pixels, max_pixels=max_pixels, ) image = image.resize((resized_width, resized_height))
smart_resize() 只要获得新的图片 resize 尺寸,使其满足以下条件:
高度和宽度都能被指定的“factor”整除;
图像的总像素数处于[min_pixels, max_pixels]的范围内;
尽可能保持图像的原始宽高比不变。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 IMAGE_FACTOR = 28 MIN_PIXELS = 4 * 28 * 28 MAX_PIXELS = 16384 * 28 * 28 MAX_RATIO = 200 def smart_resize ( height: int , width: int , factor: int = IMAGE_FACTOR, min_pixels: int = MIN_PIXELS, max_pixels: int = MAX_PIXELS tuple [int , int ]: """ Rescales the image so that the following conditions are met: 1. Both dimensions (height and width) are divisible by 'factor'. 2. The total number of pixels is within the range ['min_pixels', 'max_pixels']. 3. The aspect ratio of the image is maintained as closely as possible. """ if max (height, width) / min (height, width) > MAX_RATIO: raise ValueError( f"absolute aspect ratio must be smaller than {MAX_RATIO} , got {max (height, width) / min (height, width)} " ) h_bar = max (factor, round_by_factor(height, factor)) w_bar = max (factor, round_by_factor(width, factor)) if h_bar * w_bar > max_pixels: beta = math.sqrt((height * width) / max_pixels) h_bar = floor_by_factor(height / beta, factor) w_bar = floor_by_factor(width / beta, factor) elif h_bar * w_bar < min_pixels: beta = math.sqrt(min_pixels / (height * width)) h_bar = ceil_by_factor(height * beta, factor) w_bar = ceil_by_factor(width * beta, factor) return h_bar, w_bar def round_by_factor (number: int , factor: int ) -> int : """Returns the closest integer to 'number' that is divisible by 'factor'.""" return round (number / factor) * factor def ceil_by_factor (number: int , factor: int ) -> int : """Returns the smallest integer greater than or equal to 'number' that is divisible by 'factor'.""" return math.ceil(number / factor) * factor def floor_by_factor (number: int , factor: int ) -> int : """Returns the largest integer less than or equal to 'number' that is divisible by 'factor'.""" return math.floor(number / factor) * factor
factor 是 28, 是 patch size (14) 的两倍,由于 qwen-vl 要把相邻 2*2 的 patch 合并。主要的关键操作,就是把图片的尺寸进行调整。
Furthermore, to reduce the visual tokens of each image, a simple MLP layer is employed after the ViT to compress adjacent 2 × 2 tokens into a single token
上面代码返回
1 [<PIL.Image.Image image mode =RGB size =2044x1372 >
2044 和 1372 都是可以被 28 整除的。
text & image 模态预处理 1 2 3 4 5 6 7 8 9 10 11 12 inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True , return_tensors="pt" , ) inputs = inputs.to(model.device) for k, v in inputs.items(): if isinstance (v, torch.Tensor): print (f"{k} : {v.shape} {v.dtype} " )
输出是这样的
1 2 3 4 input_ids: torch.Size([1, 3602]) torch.int64 attention_ mask: torch.Size([1, 3602]) torch.int64pixel_values: torch.Size([14308, 1176]) torch.float32 image_ grid_thw: torch.Size([1, 3]) torch.int64
首先 processor.__call__() 会执行图片的预处理 image_processor.__call__()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 if images is not None : image_inputs = self .image_processor(images=images, videos=None , **output_kwargs["images_kwargs" ]) image_grid_thw = image_inputs["image_grid_thw" ] else : image_inputs = {} image_grid_thw = None image_processor` 不可跳转,可以打印 `processor.image_processor` 来显示类 `Qwen2VLImageProcessor Qwen2VLImageProcessor { "do_convert_rgb" : true, "do_normalize" : true, "do_rescale" : true, "do_resize" : true, "image_mean" : [ 0.48145466 , 0.4578275 , 0.40821073 ], "image_processor_type" : "Qwen2VLImageProcessor" , "image_std" : [ 0.26862954 , 0.26130258 , 0.27577711 ], "max_pixels" : 12845056 , "merge_size" : 2 , "min_pixels" : 3136 , "patch_size" : 14 , "processor_class" : "Qwen2_5_VLProcessor" , "resample" : 3 , "rescale_factor" : 0.00392156862745098 , "size" : { "longest_edge" : 12845056 , "shortest_edge" : 3136 }, "temporal_patch_size" : 2 }
image_processor.__call__() 内部也是一大堆处理,首先是正常的处理图片。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 images = make_list_of_images(images) if do_convert_rgb: images = [convert_to_rgb(image) for image in images] images = [to_numpy_array(image) for image in images] height, width = get_image_size(images[0 ], channel_dim=input_data_format) resized_height, resized_width = height, width processed_images = [] for image in images: if do_resize: resized_height, resized_width = smart_resize( height, width, factor=patch_size * merge_size, min_pixels=size["shortest_edge" ], max_pixels=size["longest_edge" ], ) image = resize( image, size=(resized_height, resized_width), resample=resample, input_data_format=input_data_format ) if do_rescale: image = self .rescale(image, scale=rescale_factor, input_data_format=input_data_format) if do_normalize: image = self .normalize( image=image, mean=image_mean, std=image_std, input_data_format=input_data_format ) image = to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format) processed_images.append(image)
processed_images 形状是 [(3, 1372, 2044)], 接下来
1 2 3 4 5 6 7 patches = np.array(processed_images) if data_format == ChannelDimension.LAST: patches = patches.transpose(0 , 3 , 1 , 2 ) if patches.shape[0 ] % temporal_patch_size != 0 : repeats = np.repeat(patches[-1 ][np.newaxis], temporal_patch_size - 1 , axis=0 ) patches = np.concatenate([patches, repeats], axis=0 )
这段代码先将所有图片变成一个numpy array,然后判断第一维是否为 temporal_patch_size 的倍数, 不是的话复制最后一个 patches 元素 patches[-1], 并拼接回原数组。这是因为Qwen2-VL把视频当作一秒两帧的图片集合,为了统一框架,需要把图片复制成两个相同的帧(相当于图片 —> 一秒钟视频)。
To preserve video information as completely as possible, we sampled each video at two frames per second. Additionally, we integrated 3D convolutions (Carreira and Zisserman, 2017) with a depth of two to process video inputs, allowing the model to handle 3D tubes instead of 2D patches, thus enabling it to process more video frames without increasing the sequence length (Arnab et al., 2021). For consistency, each image is treated as two identical frames.
之后就是 reshape 为真正以上的 patch。每一个patch的大小是(channel * self.temporal_patch_size * self.patch_size * self.patch_size),temporal_patch_size 默认为 2,channel 也不参与划分,所以相当于对于图片来说,patchify 只在 h 和 w 维度进行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 grid_t = patches.shape[0 ] // temporal_patch_size grid_h, grid_w = resized_height // patch_size, resized_width // patch_size patches = patches.reshape( grid_t, temporal_patch_size, channel, grid_h // merge_size, merge_size, patch_size, grid_w // merge_size, merge_size, patch_size, ) patches = patches.transpose(0 , 3 , 6 , 4 , 7 , 2 , 1 , 5 , 8 ) flatten_patches = patches.reshape( grid_t * grid_h * grid_w, channel * temporal_patch_size * patch_size * patch_size ) return flatten_patches, (grid_t, grid_h, grid_w)
image_grid_thw = image_inputs["image_grid_thw"] 即 (grid_t, grid_h, grid_w) or [1, 98, 146],即 patch 在时序、高度、宽度上的数量。1372/14=98, 2044/14=146
接下来就是用特殊符号 <|placeholder|> 来暂时占位,原先 self.image_token 即 <|image_pad|> 只有一个,需要为实际的 image patch embedding 来预留位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 if image_grid_thw is not None :merge_length = self .image_processor.merge_size**2 index = 0 for i in range (len (text)): while self .image_token in text[i]: text[i] = text[i].replace( self .image_token, "<|placeholder|>" * (image_grid_thw[index].prod() // merge_length), 1 , ) index += 1 text[i] = text[i].replace("<|placeholder|>" , self .image_token) text_inputs = self .tokenizer(text, **output_kwargs["text_kwargs" ])
merge_length 就是根据将相邻 self.image_processor.merge_size * merge_size 的 patch 组合的每组的 patch 数量。这里最后还是类似纯文本模型的 tokenize,结果是 <|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|>...<|image_pad|><|vision_end|>Describe this image.<|im_end|>\n<|im_start|>assistant\n 我把中间的 <|image_pad|> 省略了。
输入的 [3, 2044, 1372] 维的图片变成了 [14308, 1176] 的 pixel_value,最终输入语言模型的视觉 token 数是 14308/4=3577, 其实就是原本的大小除以 28x28, 即(1372/14) x (2044/14) = 98x146 = 14308。而 1176 = 3x14x14x2 (channel x temporal_patch_size x patch_size x .patch_size), 是 3D 卷积的处理。
1 2 generated_ids = model.generate(**inputs, max_new_tokens=128 )
image encoder 前向过程 以下是 Qwen2_5_VLForConditionalGeneration.forward() 的的一部分内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 inputs_embeds = self .model.embed_tokens(input_ids) if pixel_values is not None : pixel_values = pixel_values.type (self .visual.dtype) image_embeds = self .visual(pixel_values, grid_thw=image_grid_thw) n_image_tokens = (input_ids == self .config.image_token_id).sum ().item() n_image_features = image_embeds.shape[0 ] if n_image_tokens != n_image_features: raise ValueError( f"Image features and image tokens do not match: tokens: {n_image_tokens} , features {n_image_features} " ) mask = input_ids == self .config.image_token_id mask_unsqueezed = mask.unsqueeze(-1 ) mask_expanded = mask_unsqueezed.expand_as(inputs_embeds) image_mask = mask_expanded.to(inputs_embeds.device) image_embeds = image_embeds.to(inputs_embeds.device, inputs_embeds.dtype) inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)
self.visual 和 self.model 分别为视觉和文本的模型。 self.visual(pixel_values, grid_thw=image_grid_thw) 转入Qwen2_5_VisionTransformerPretrainedModel.forward()。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 hidden_states = self .patch_embed(hidden_states) rotary_pos_emb = self .rot_pos_emb(grid_thw) window_index, cu_window_seqlens = self .get_window_index(grid_thw) cu_window_seqlens = torch.tensor( cu_window_seqlens, device=hidden_states.device, dtype=grid_thw.dtype if torch.jit.is_tracing() else torch.int32, ) cu_window_seqlens = torch.unique_consecutive(cu_window_seqlens) seq_len, _ = hidden_states.size() hidden_states = hidden_states.reshape(seq_len // self .spatial_merge_unit, self .spatial_merge_unit, -1 ) hidden_states = hidden_states[window_index, :, :] hidden_states = hidden_states.reshape(seq_len, -1 ) rotary_pos_emb = rotary_pos_emb.reshape(seq_len // self .spatial_merge_unit, self .spatial_merge_unit, -1 ) rotary_pos_emb = rotary_pos_emb[window_index, :, :] rotary_pos_emb = rotary_pos_emb.reshape(seq_len, -1 ) emb = torch.cat((rotary_pos_emb, rotary_pos_emb), dim=-1 ) position_embeddings = (emb.cos(), emb.sin()) cu_seqlens = torch.repeat_interleave(grid_thw[:, 1 ] * grid_thw[:, 2 ], grid_thw[:, 0 ]).cumsum( dim=0 , dtype=grid_thw.dtype if torch.jit.is_tracing() else torch.int32, ) cu_seqlens = F.pad(cu_seqlens, (1 , 0 ), value=0 ) for layer_num, blk in enumerate (self .blocks): if layer_num in self .fullatt_block_indexes: cu_seqlens_now = cu_seqlens else : cu_seqlens_now = cu_window_seqlens if self .gradient_checkpointing and self .training: hidden_states = self ._gradient_checkpointing_func( blk.__call__, hidden_states, cu_seqlens_now, None , position_embeddings ) else : hidden_states = blk(hidden_states, cu_seqlens=cu_seqlens_now, position_embeddings=position_embeddings) hidden_states = self .merger(hidden_states) reverse_indices = torch.argsort(window_index) hidden_states = hidden_states[reverse_indices, :] return hidden_states
hidden_states 在正常 transformer block 前向传播后形状为 [14308, 1280], 经过 merger (两层的 MLP), 期间通过 reshape 变成了 [3577, 5120], 经过 MLP 后变成了 [3577, 2048],embedding 维度就和文本一致了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Qwen2_5_VLPatchMerger (nn.Module): def __init__ (self, dim: int , context_dim: int , spatial_merge_size: int = 2 ) -> None : super ().__init__() self .hidden_size = context_dim * (spatial_merge_size**2 ) self .ln_q = Qwen2RMSNorm(context_dim, eps=1e-6 ) self .mlp = nn.Sequential( nn.Linear(self .hidden_size, self .hidden_size), nn.GELU(), nn.Linear(self .hidden_size, dim), ) def forward (self, x: torch.Tensor ) -> torch.Tensor: x = self .mlp(self .ln_q(x).view(-1 , self .hidden_size)) return x
接着返回是 Qwen2_5_VLForConditionalGeneration.forward() 的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 inputs_embeds = self .model.embed_tokens(input_ids) if pixel_values is not None : pixel_values = pixel_values.type (self .visual.dtype) image_embeds = self .visual(pixel_values, grid_thw=image_grid_thw) n_image_tokens = (input_ids == self .config.image_token_id).sum ().item() n_image_features = image_embeds.shape[0 ] if n_image_tokens != n_image_features: raise ValueError( f"Image features and image tokens do not match: tokens: {n_image_tokens} , features {n_image_features} " ) mask = input_ids == self .config.image_token_id mask_unsqueezed = mask.unsqueeze(-1 ) mask_expanded = mask_unsqueezed.expand_as(inputs_embeds) image_mask = mask_expanded.to(inputs_embeds.device) image_embeds = image_embeds.to(inputs_embeds.device, inputs_embeds.dtype) inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)
在 image_embeds 计算完后,检查预留的 image token 数量是否和计算的 image_embeds 数量相同 (预处理时根据 image size 预留了 image token),之后创建一个和 inputs_embeds 形状完全一样的 mask(mask_expanded), 之后就将 image_embeds 赋值到对应位置,这样 text embedding 和 image embedding 正式结合在 unimodal latent space 里,其实就是 text embedding space。之后就是正常的 forward。
以下时 3D-rope 的计算过程,不是本文重点所以不讲了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 if position_ids is None and (attention_mask is None or attention_mask.ndim == 2 ): if ( (cache_position is not None and cache_position[0 ] == 0 ) or self .rope_deltas is None or (past_key_values is None or past_key_values.get_seq_length() == 0 ) ): position_ids, rope_deltas = self .get_rope_index( input_ids, image_grid_thw, video_grid_thw, second_per_grid_ts, attention_mask, ) self .rope_deltas = rope_deltas else : batch_size, seq_length, _ = inputs_embeds.shape delta = ( (cache_position[0 ] + self .rope_deltas).to(inputs_embeds.device) if cache_position is not None else 0 ) position_ids = torch.arange(seq_length, device=inputs_embeds.device) position_ids = position_ids.view(1 , -1 ).expand(batch_size, -1 ) if cache_position is not None : delta = delta.repeat_interleave(batch_size // delta.shape[0 ], dim=0 ) position_ids = position_ids.add(delta) position_ids = position_ids.unsqueeze(0 ).expand(3 , -1 , -1 ) outputs = self .model( input_ids=None , position_ids=position_ids, attention_mask=attention_mask, past_key_values=past_key_values, inputs_embeds=inputs_embeds, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, cache_position=cache_position, )
之后就是经典的 shift label 交叉熵。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 hidden_states = outputs[0 ] logits = self .lm_head(hidden_states) loss = None if labels is not None : logits = logits.float () shift_logits = logits[..., :-1 , :].contiguous() shift_labels = labels[..., 1 :].contiguous() loss_fct = CrossEntropyLoss() shift_logits = shift_logits.view(-1 , self .config.vocab_size) shift_labels = shift_labels.view(-1 ) shift_labels = shift_labels.to(shift_logits.device) loss = loss_fct(shift_logits, shift_labels) if not return_dict: output = (logits,) + outputs[1 :] return (loss,) + output if loss is not None else output return Qwen2_5_VLCausalLMOutputWithPast( loss=loss, logits=logits, past_key_values=outputs.past_key_values, hidden_states=outputs.hidden_states, attentions=outputs.attentions, rope_deltas=self .rope_deltas, )
后处理 - 解码 token id 1 2 3 4 5 6 7 generated_ids_trimmed = [ out_ids[len (in_ids) :] for in_ids, out_ids in zip (inputs.input_ids, generated_ids) ] output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True , clean_up_tokenization_spaces=False ) print (output_text)
因为上述代码都是 batch 输入的,generated_ids_trimmed 简而言之就是把 input_ids 截断,保留新产生的 token id。
1 ['The image depicts a serene beach scene with a person and a dog. The person is sitting on the sandy beach, facing the ocean. They are wearing a plaid shirt and black pants, and they have long hair. The dog, which appears to be a Labrador Retriever, is sitting on the sand and is interacting with the person by placing its paw on their hand. The dog is wearing a harness with a colorful collar. The background shows the ocean with gentle waves, and the sky is clear with a soft light, suggesting it might be early morning or late afternoon. The overall atmosphere of the image is peaceful and joyful.']