
对比学习在CV与NLP领域的应用:SimCLR、SimCSE 与 SimVLM
对比学习作为一种重要的自监督预训练范式,已在计算机视觉(CV)与自然语言处理(NLP)等多个领域展现出强大能力。本文将聚焦三种经典代表方法:SimCLR、SimCSE 及 SimVLM,探讨其核心思想与技术实现。
SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
InfoNCE
InfoNCE(Information Noise-Contrastive Estimation)是一种对比损失函数,用于训练通过区分正负样本对来学习表征的模型。其最初被提出用于自监督学习场景中。
对于一个锚点 (anchor) 样本
PS:复杂公式渲染比较失败,我把公式在我本地正常渲染的图片也放进来
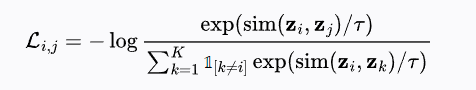
其中:
:通常为余弦相似度; :温度超参数,用于控制分布的尖锐程度; :指示函数,避免样本与自身比较。
InfoNCE 通常默认使用同一批次内的非正样本作为负样本,无需人工标注负对。该损失函数鼓励模型将正样本对拉近,而将负样本对在嵌入空间中推远。
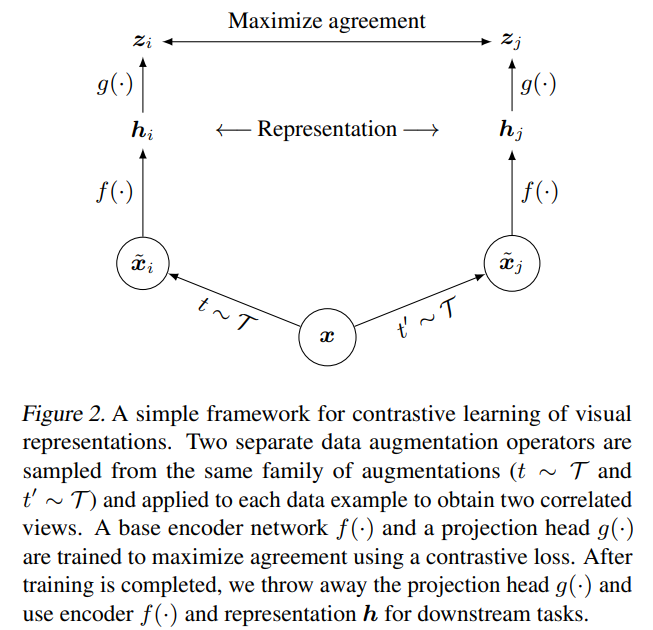
SimCLR CV领域的对比学习
We simplify recently proposed contrastive selfsupervised learning algorithms without requiring specialized architectures or a memory bank.
we systematically study the major components of our framework. We show that (1) composition of data augmentations plays a critical role in defining effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations, and (3) contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning.
SimCLR 是一种简化的对比自监督学习方法,其不依赖于特殊架构或内存机制,并系统性地分析了其关键组成部分。研究表明:
- 数据增强的组合对定义有效的预测任务至关重要;
- 在表征与对比损失之间引入可学习的非线性变换有助于提升学习质量;
- 对比学习在大批量和更长训练周期下优于监督学习。
将这些因素结合后,SimCLR 在 ImageNet 上大幅超越了以往的自监督和半监督方法。在该方法学习到的表征基础上训练的线性分类器可达到 76.5% 的 top-1 准确率,比当时的 SOTA 高 7%,甚至可与监督训练的 ResNet-50 相媲美。
Composition of multiple data augmentation operations is crucial in defining the contrastive prediction tasks that yield effective representations. In addition, unsupervised contrastive learning benefits from stronger data augmentation than supervised learning.
SimCLR 的核心流程如下:
使用随机数据增强模块生成两种相关视图(作为正样本对),增强操作依次为:随机裁剪+恢复尺寸、颜色扰动、高斯模糊;
使用编码器(如 ResNet)提取表示:
- 使用两层 MLP 投影头生成对比空间中的嵌入:
一个批次包含 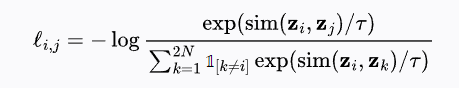
其中:
:表示正样本对 的对比损失; :表示嵌入向量之间的相似度(例如余弦相似度); :温度系数; :指示函数,当 时为 1,否则为 0; :表示总样本数,可能包括原始样本和其增强版本。

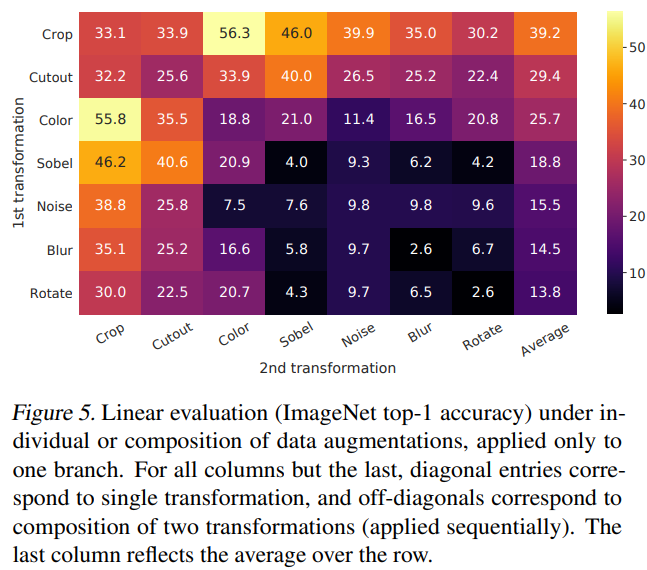
为了系统地研究数据增强的影响,作者考虑了几种常见的数据增强方式。一类增强属于空间/几何变换,例如裁剪与缩放(含水平翻转)、旋转和 cutout;另一类则属于外观变换,例如颜色扰动(包括去色、亮度、对比度、饱和度和色调变化)、高斯模糊和 Sobel 滤波。
为了理解单个增强方式的效果以及增强组合的重要性,作者对比了分别使用单一增强和组合增强的模型性能。结果表明,单独的一种变换不足以学习出高质量的表征,尽管模型几乎可以完美识别出正样本对。而当使用组合增强时,尽管对比预测任务变得更加困难,但最终学习到的表征质量却显著提升。注意对角线是单独变换,非对角线是组合变换,最后一列是平均效果,明显对角线都会比平均效果差,代表组合变化对于表征学习更好,虽然会让任务变难。
SimCSE NLP领域的对比学习
首先,作者提出了一种无监督方法,该方法将输入句子作为自身的预测目标,并在对比学习目标下仅使用标准的 dropout 作为噪声。实验发现,dropout 起到了最小的数据增强作用,一旦移除 dropout,会导致表征坍缩(representation collapse),即表征的有效性不强了。
随后,作者提出了一种有监督方法,将自然语言推理(NLI)数据集中的标注句对引入对比学习框架。其中,“蕴含”(entailment)句对被用作正样本,而“矛盾”(contradiction)句对则作为 hard negative。
在 NLI 任务中,前提句与假设句之间的关系可分为三类:蕴含、矛盾和中性。蕴含表示假设句可以从前提句推出;矛盾表示假设句的否定可以从前提句推出;中性则表示无法判断是否成立或矛盾。SimCSE 利用蕴含对可自然作为正样本的特点,同时发现引入对应的矛盾对作为 hard negatives 可进一步提升性能。作者指出,无监督的 SimCSE 通过 dropout 噪声在避免表征塌缩的同时提升了表征空间的均匀性,从而增强了表示的表达能力。
Unsupervised SimCSE
在对比学习中,一个关键问题是如何构造正样本对。在视觉表征中,一个有效的做法是对同一图像进行两种随机变换(例如裁剪、翻转、扭曲或旋转),然后将其视为正样本对。类似的策略也被引入到了语言表征中,通过词语删除、词序打乱、替换等增强方式构造语言的正样本。然而,由于语言的离散性,NLP 中的数据增强本质上更为困难。在 SimCSE 中,作者发现仅使用标准的 dropout 对中间表征施加扰动,就能优于上述离散增强方法。
在标准的 Transformer 训练中,dropout mask 被应用于全连接层以及注意力概率上。
设 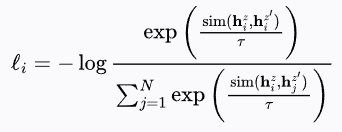
作者将 dropout 视为一种最小形式的数据增强:正样本对使用完全相同的输入句子,其表示之间仅由不同的 dropout mask 引入差异。常见的数据增强方式,如裁剪、词语删除或替换,可以形式化为
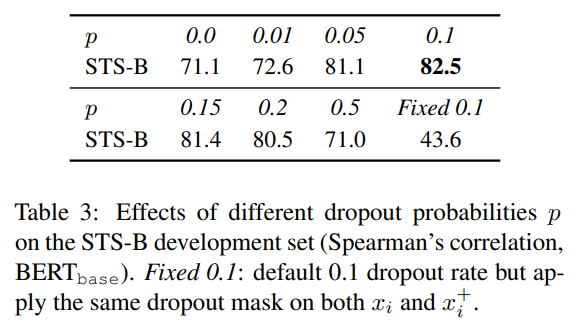
作者进一步尝试了不同的 dropout 概率,发现所有变化形式的效果均低于 Transformer 默认的

作者还在训练过程中每隔 10 步保存一次模型,并可视化 alignment(对齐性)与 uniformity(均匀性)两个指标。结果显示,从预训练参数出发,所有模型都能显著提升均匀性,但上述两个特殊变体的 alignment 指标迅速退化,而无监督 SimCSE 由于引入了 dropout 噪声,保持了良好的对齐性。
Supervised SimCSE
作者已经证明,引入 dropout 噪声能够在正样本对之间保持良好的对齐性。因此,进一步探讨是否可以利用有监督的数据集,提供更强的训练信号以提升对齐质量。以往的研究已表明,自然语言推理(NLI)任务中的有监督数据在学习句子嵌入方面非常有效,其任务目标是判断两个句子之间的关系属于“蕴含”“中性”还是“矛盾”。
在 SimCSE 的有监督版本中,作者直接使用 NLI 数据集中的蕴含 entailment 对作为正样本,并进一步利用其中的矛盾 contradiction 对作为 hard negative,增强对比学习的难度和效果。
形式上,将二元组 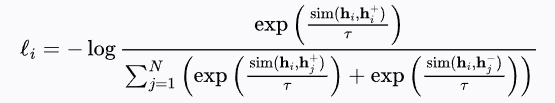
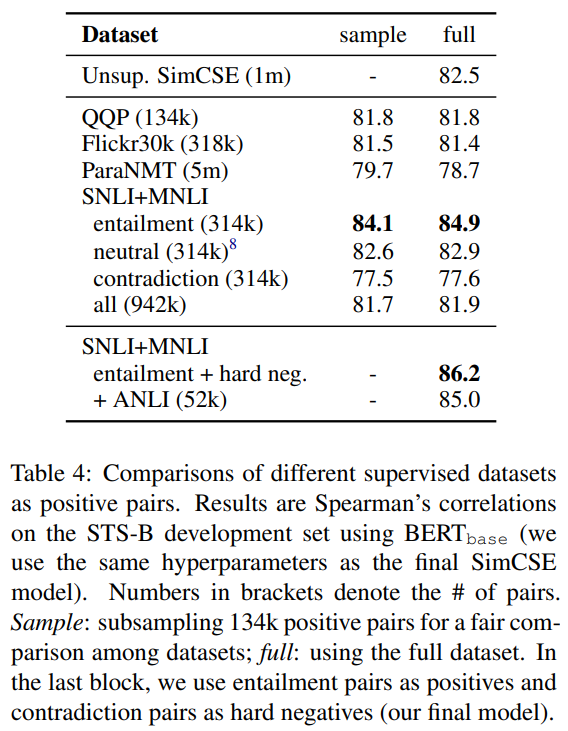
引入 hard negative 可以进一步提升模型性能(例如在 STS-B 任务中由 84.9 提升至 86.2),这也构成了最终的有监督 SimCSE 方法。
如今,许多 RAG(Retrieval-Augmented Generation)系统中的检索器也采用类似的有监督对比学习策略进行训练,使用问题-正向文段对作为正样本,并结合同批次中的其他样本作为负样本——这一方式与 SimCSE 的有监督训练模式非常相似。
| 项目 | Unsupervised SimCSE | Supervised SimCSE |
|---|---|---|
| 正样本 (Positive Pairs) | 同一句子经过两次独立 Dropout 的编码表示(即: |
来自 NLI 数据中的蕴含对 |
| 负样本 (Negative Pairs) | In-batch negatives:同一 mini-batch 中其他句子(不同语义)自动构成负样本 | NLI 中的矛盾对 |
| 训练目标 | InfoNCE 损失,最大化相同句子(不同 dropout)间的相似度,最小化与 batch 中其他句子的相似度 | 变种的对比损失,最大化 |
| 数据来源 | 原始无标签语料(如 Wikipedia) | 有标注的 NLI 数据集(如 MNLI) |
| 监督信号 | 无 | 有(entailment/contradiction) |
| 训练稳定性 | 对 batch size、dropout 敏感 | 更稳定,有明确正负标签 |
SimVLM VLM领域的对比学习
随着视觉与文本联合建模技术的不断进展,视觉-语言预训练(Vision-Language Pretraining, VLP)在众多多模态下游任务中已取得显著成果。然而,现有方法通常依赖高成本的标注数据,如干净的图文描述和区域标签,这极大限制了其可扩展性。此外,为适配不同数据集目标而引入的多种任务目标,也使得预训练过程变得更加复杂。
在 VLP 领域,虽然提出了多种不同方法,但其中很大一部分都需要引入目标检测模型,来回归图像区域特征或进行标签预测,作为预训练任务的一部分。这类方法通常依赖于如 Fast R-CNN 或 Faster R-CNN 等强大的目标检测器,而这些检测器本身也需依赖人工标注数据进行训练。将这类标注数据作为预训练的前置条件,既增加了训练流程的成本,也进一步限制了方法的扩展性。
尽管近期已有部分研究尝试摆脱目标检测模块,但这类方法多仅依赖于小规模、干净的图文数据,因此其零样本能力受到限制。另一方面,多数方法还提出了跨模态损失函数,但这些损失往往与图像描述生成、掩码语言建模等其他目标混合使用,从而形成复合的预训练损失。这种多任务、多数据集的组合增加了权重平衡与优化的难度。
因此,早期的视觉-语言预训练方法大致可归为两类:一类通过引入中间的 CV 任务,另一类则构造复杂的跨模态损失。SimVLM 则试图简化这一预训练流程。
与先前工作不同,SimVLM 利用大规模弱监督图文对,采用单一的前缀语言建模(Prefix Language Modeling)目标实现端到端训练,显著降低训练复杂度。在不依赖额外数据或任务定制的前提下,该模型在多种判别式与生成式视觉-语言任务上超越已有方法,达到了新的 SOTA 水平。
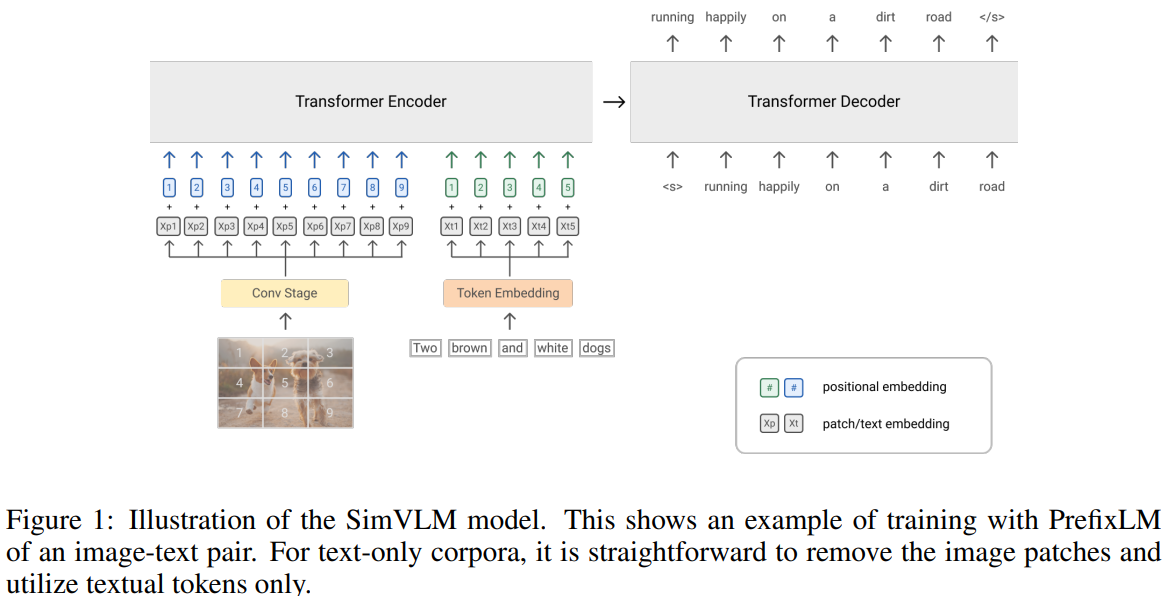
受益于语言建模损失(LM loss)在预训练中所展现出的零样本能力,作者提出使用前缀语言建模(Prefix Language Modeling,PrefixLM)对视觉-语言表征进行预训练。PrefixLM 相较于标准语言建模的区别在于:它允许对前缀序列(如公式中的 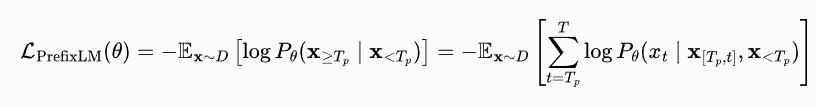
直观来看,图像通常在网页等真实文档中出现在文本之前,因此可将图像视为文本的前缀。对于给定的图文对,模型将图像特征序列(长度为
模型主干采用 Transformer 架构,因其在语言与视觉任务中均表现出色。与标准语言模型不同,PrefixLM 允许在前缀内进行双向注意力,因此可兼容仅使用解码器(decoder-only)或编码-解码器(encoder-decoder)的序列到序列模型。实验发现,编码-解码结构所引入的 inductive bias(将编码与生成过程解耦)对于提升下游任务性能具有积极作用。
在视觉模态方面,受 ViT 启发,模型将输入图像
在文本模态方面,还是和正常模型一样。为了保留位置信息,模型为图像与文本输入分别引入了两个可学习的一维位置编码,并在 Transformer 层中为图像 patch 增加了二维相对注意力机制。
与以往需要两个预训练阶段和多个辅助目标的 VLP 方法相比,SimVLM 仅需一次性预训练,并在端到端的框架下使用单一的语言建模损失函数。这种设计大大简化了训练流程,因此被命名为“Simple Visual Language Model”(SimVLM,简洁视觉语言模型)。