
Agent 概念
任何高效的 AI 系统都需要为大语言模型(LLM)提供某种接触现实世界的能力:例如,调用搜索工具以获取外部信息,或者操控特定程序来完成任务。换句话说,LLM 应当具备自主性(agency)。具备代理能力的程序,是 LLM 通向外部世界的桥梁。
代理(Agent)是指一个系统,它利用 AI 模型与环境交互,以实现用户定义的目标。它结合了推理、规划和行动执行(通常通过外部工具)来完成任务。
**AI Agent 是一种程序,其工作流程由 LLM 的输出控制。**LLM 是 Agent 的一部分,扮演其“大脑(mind)”的角色;而 Agent 本身更像是一个“工作流(workflow)”,围绕 LLM 组织了一系列模块与机制,管理从输入到输出的整个流程。
LLM 是 Agent 的组成部分,但 Agent 是围绕 LLM 构建起来的一个智能行为控制系统,它将模型的文本生成能力嵌入到了一个可交互、可执行的工作流中。
你可以将代理理解为由两个主要部分组成:
大脑(AI 模型):所有的思考都发生在这里。AI 模型负责推理和规划,并根据当前情境决定采取哪些行动(Action)。
身体(能力与工具):代表代理所配备的一切操作能力。
可执行的行为范围取决于代理被配备了什么功能。例如,人类没有翅膀,就不能执行“飞行”这个动作,但可以“走路”“奔跑”“跳跃”“抓取”等。同理,LLM 虽然很强大,但它本身只能生成文本。因此,开发者为它实现了额外功能(称为工具 Tools),通过这些工具,LLM 可以完成我们为其实现的各种动作(Actions)。
任何使用 LLM 的系统,都会将 LLM 的输出整合进代码流程中。LLM 对程序控制流程的影响程度,就是该系统中 LLM 的“自主性”水平。注意,这里的“代理”并不是一个离散的“是 / 否”状态,而是在一个连续光谱上演进的概念——你赋予 LLM 越多控制权,它的自主性就越强。
下面的表格展示了不同系统中的代理水平差异:
| 简称 | 描述 | 自主性等级 |
|---|---|---|
| 简单 LLM | LLM 的输出对程序流程没有影响 | ☆☆☆ |
| Router | LLM 输出控制一个 if/else 语句分支 | ★☆☆ |
| Tool call | LLM 输出控制某个函数的调用 | ★★☆ |
| Multi-step Agent | LLM 输出控制程序的迭代与继续执行 | ★★☆ |
| Multi-Agent | 一个代理流程可以启动另一个代理流程 | ★★★ |
| Code Agents | LLM 在代码中运行,能够定义自己的工具或启动其他代理 | ★★★ |
接下来是一个多步代理(Multi-step Agent)的代码结构示例:
(可根据需求翻译或展示代码)
1 | memory = [user_defined_task] |
该 agentic 系统在一个循环中运行,每一步执行一个新的动作(action)(这个动作通常是调用某些预设的“工具”,这些工具其实就是函数),直到根据其观察结果判断:已经达到了可以解决当前任务的满意状态为止。
Agent 如何控制工作流 - Messages and Special Tokens
message 定义
就像 ChatGPT 一样,用户通常是通过聊天界面与代理(Agent)交互的。因此,我们需要理解 LLM 是如何处理聊天内容的。当你与 ChatGPT 这样的系统对话时,你实际上是在交换消息(messages)。在幕后,这些消息会被拼接并格式化为模型可以理解的提示词(prompt)。
这正是“聊天模板(chat templates)”发挥作用的地方。它们是用户和助手之间对话消息与模型特定格式要求之间的桥梁。换句话说,聊天模板负责结构化用户与代理之间的沟通,确保每个模型(即便使用不同的特殊标记符)都能接收到正确格式的提示内容。
我们再次提到特殊标记符(special tokens),因为它们是模型用来区分用户与助手轮次开始和结束的标志。就像每个模型有自己的 EOS(End Of Sequence)标记符一样,它们对对话消息的格式和分隔符也有不同的规范。
消息通常分为以下几种类型:
System Message(系统消息,也称为系统提示词):用于定义模型应该如何行为。它们提供的是持久性指令,指导后续的所有交互。在使用代理时,系统消息还会:
- 提供有关可用工具的信息;
- 指示模型如何格式化其要采取的动作;
- 给出思考过程应如何分段的指导原则。
User 和 Assistant Messages(用户消息与助手消息):顾名思义,分别对应用户的输入与模型的响应内容。
message 格式化
可以用 tokenizer 的 apply_chat_template 函数来转换 messages,tokenize 置为 false 就不会转换为 token id, add_generation_prompt 则是为下一个 assistant 的 message 加入前缀学习,即 <|im_start|>assistant\n ,这部分属于固定格式,也相当于提示大模型接下来要输出 assistant 角色的内容。
1 | messages = [ |
1 | <|im_start|>system |
工具
工具定义
工具(Tool)是提供给大语言模型(LLM)调用的函数,每个工具都应该用于完成一个明确的目标。
以下是 AI Agent 中常用的一些工具示例:
| 工具名称 | 描述 |
|---|---|
| 网络搜索 | 允许 Agent 从互联网上获取最新信息。 |
| 图像生成 | 根据文本描述生成图像。 |
| 信息检索 | 从外部知识库中检索信息。 |
| API 接口 | 与外部服务的 API(如 GitHub、YouTube、Spotify 等)交互。 |
一个好的工具应当是对大语言模型能力的补充。例如,当你需要执行算术运算时,提供一个计算器工具比依赖 LLM 自身的推理能力更能获得稳定准确的结果。
工具的存在是为了弥补大模型的能力不足或缺陷,或仅仅是为了确保结果更加稳定与正确。
此外,LLM 是基于训练数据来预测 prompt 的补全结果,这意味着它的内部知识只能覆盖训练数据之前的事件。因此,如果你的 Agent 需要访问实时数据,你必须通过工具提供这些数据。举例来说,如果你问 LLM“今天巴黎的天气如何”,而没有接入搜索工具,那么它可能会凭空捏造一个天气情况(hallucination)。
一个工具应包含以下内容:
- 对函数功能的文字描述;
- 一个可调用对象(Callable);
- 带类型标注的参数(Arguments);
- (可选)带类型标注的输出(Outputs)。
需要注意的是,LLM 只能接受文本输入并生成文本输出,它自身无法主动调用工具。
所谓“给 Agent 提供工具”,其实是指:教会 LLM 这些工具的存在,并在需要时引导其生成基于文本的调用指令。
例如,假设你提供了一个可以查询实时天气的工具,然后问模型“巴黎今天的天气如何?”,LLM 会意识到这是一次调用“天气工具”的机会。它不会自己返回天气数据,而是生成类似 call weather_tool('Paris') 的调用文本。
这时,Agent 系统会读取 LLM 的输出,识别出需要调用工具,代表 LLM 执行实际的工具函数调用,并获取真实的天气信息。
工具调用的过程通常不会展示给用户:Agent 会将调用结果作为一个新消息追加进对话历史,并将更新后的对话再次传入 LLM。这时 LLM 会根据新的上下文生成自然流畅的最终答复。
从用户的角度来看,似乎是 LLM 直接调用了工具,但实际上,整个工具调用过程是由 Agent 在后台完成的。
至于大模型怎么知道去调用这些工具,除了需要微调外,最初的要求是把工具告诉大模型。以下就是一个带工具说明的 system message:
1 | system_message = "You are an AI assistant. Your primary goal is to provide helpful, precise and clear respones. |
要使工具调用机制正常运作,我们必须非常准确和明确地定义以下几点:
- 工具的功能是什么
- 它需要什么样的输入
- 它会输出什么类型的结果
正因如此,工具的描述通常采用既具表达力又精准的结构,例如编程语言格式或 JSON 结构。 这并不是说必须使用这些格式,任何精确且结构一致的格式都是可行的。
工具实现 - 功能和描述
1 | def calculator(a: int, b: int) -> int: |
该工具需要以下输入:
a(int):一个整数b(int):一个整数
该工具的输出是一个整数,可以描述如下:
- (int):
a与b的乘积。
我们可以用以下字符串来描述这个 tool
1 | Tool Name: calculator, Description: Multiply two integers., Arguments: a: int, b: int, Outputs: int |
但为了更规范化的获取 tool 描述,可以为 tool 包装为 class
1 | from typing import Callable |
更好的方式是 python 修饰器,decorator,用修饰器修饰函数,就可实现统一的一些功能
1 | from functools import wraps |
1 | Tool name: calculator |
Agent 周期 Thought-Action-Observation
周期概述
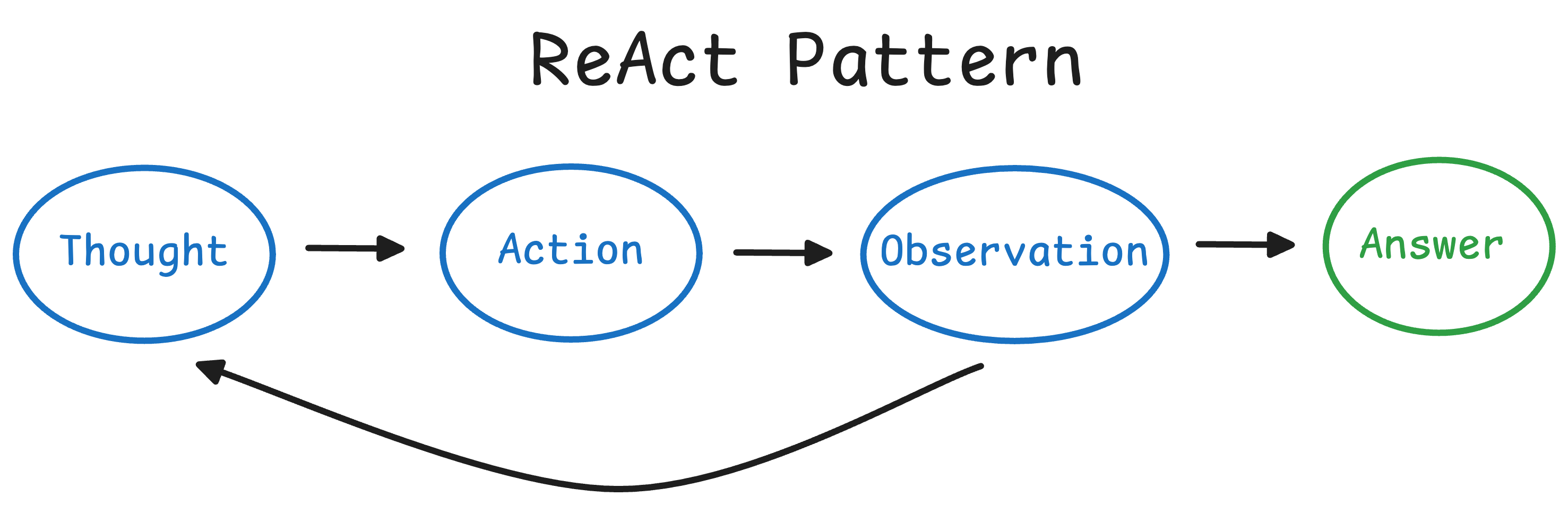
Agent 以**思考(Thought)→ 行动(Action)→ 观察(Observation)**的连续循环方式运行。
我们来逐步拆解这些步骤:
- Thought(思考):Agent 中的大语言模型部分决定下一步应该做什么。
- Action(行动):Agent 执行一个动作,即调用相应工具并传入对应参数。
- Observation(观察):模型对工具返回的结果进行反思和处理。
在许多 Agent 框架中,这些规则与流程会直接嵌入到系统提示词(system prompt)中,以确保每一次循环都遵循预设的逻辑。
1 | system_message=""" |
我们可以看到,在 System Message 中我们定义了:
- Agent 的行为方式;
- Agent 可使用的工具;
- 思考–行动–观察(Thought-Action-Observation)循环,并将其嵌入到了对 LLM 的指令中。
为什么需要 thought
*Thought(思考)代表了 Agent 为了解决任务而进行的*内部推理与规划过程。它依赖于 Agent 所用的大语言模型(LLM)在 prompt 中提供的信息上进行*分析与理解。你可以将其看作 Agent 的*内心独白,在其中它思考手头的任务并制定行动策略。
Agent 的思考部分负责利用当前的观察信息,决定接下来的行动。通过这个过程,Agent 可以:
- 将复杂问题拆解为更易管理的子任务;
- 回顾过往经验;
- 根据新信息不断调整其策略。
以下是一些常见的思考类型及示例:
| 思考类型 | 示例 |
|---|---|
| 规划(Planning) | “我需要将这个任务分成三步:1)收集数据,2)分析趋势,3)生成报告。” |
| 分析(Analysis) | “根据错误信息来看,问题可能出在数据库连接参数上。” |
| 决策(Decision) | “考虑到用户的预算限制,我应该推荐中档方案。” |
| 问题解决(Problem Solving) | “要优化这段代码,我应该先做性能分析找出瓶颈。” |
| 记忆整合(Memory Integration) | “用户之前提到偏好 Python,所以我将用 Python 举例。” |
| 自我反思(Self-Reflection) | “我上一次的方法效果不好,应该换一种策略尝试。” |
| 目标设定(Goal Setting) | “完成这个任务前,我需要先明确验收标准。” |
| 优先级排序(Prioritization) | “安全漏洞应在添加新功能之前优先修复。” |
对于专门为函数调用(function-calling)微调过的 LLM,这种“思考过程”并非强制必须的。
一种关键方法是 ReAct 方法,即将“推理(Reasoning)”与“行动(Acting)”结合。这是一种简单的提示技术:在模型解码前加一句 “Let’s think step by step”(让我们一步步思考)。
这种方式鼓励模型生成的下一个 token 更倾向于生成一个计划,而不是直接给出最终答案。因为模型被引导去分解问题为子任务,从而使它在处理复杂问题时能更加细致,通常比直接输出最终答案更少出错。

Action
Action 类型
**Action(行动)*是 AI Agent 用来*与外部环境交互的具体操作步骤。
无论是上网搜索信息,还是控制某个物理设备,每一个 Action 都是 Agent 有意执行的操作。
例如,一个客户服务 Agent 可能会执行以下操作:检索客户数据、提供帮助文章,或将问题转交给人工客服。
不同类型的 Agent 在执行 Action 时方式不同:
| Agent 类型 | 描述 |
|---|---|
| JSON Agent | 所需执行的 Action 以 JSON 格式指定。 |
| Code Agent | Agent 编写一段代码,由外部系统解释执行。 |
| Function-calling Agent | 属于 JSON Agent 的一个子类型,经过微调后为每个 Action 生成一个新消息。它是 OpenAI 提供的一种更严格、有组织的格式。 |
Action 的用途多种多样,例如:
| Action 类型 | 描述 |
|---|---|
| 信息获取(Information Gathering) | 执行网页搜索、查询数据库、检索文档等操作。 |
| 工具调用(Tool Usage) | 调用 API、执行计算、运行代码等操作。 |
| 环境交互(Environment Interaction) | 操控数字界面或控制实体设备等。 |
| 信息沟通(Communication) | 通过聊天与用户互动,或与其他 Agent 协作。 |
值得注意的是,LLM 本身只能处理文本,它会使用文本来描述想要执行的 Action 以及所需的参数。
为了让 Agent 正常运行,LLM 必须在完整生成一个 Action 所需的所有 tokens 后停止解码,然后将控制权交还给 Agent。 这一步至关重要,因为它确保了生成结果是可解析的——无论该格式是 JSON、代码还是函数调用(function-calling)。
暂停-解析
实现 Action 的一个关键方法是 “停止并解析(stop and parse)”机制。
这种方法确保 Agent 的输出是结构化且可预测的,主要包括以下三个步骤:
- 以结构化格式生成输出:Agent 以明确、预先定义的格式(如 JSON 或代码)输出其要执行的动作。
- 停止进一步生成:当动作的文本已完全生成后,LLM 停止继续生成 token,以避免多余或错误的输出。
- 解析输出内容:由外部的解析器读取结构化的动作文本,确定需要调用哪个工具,并提取所需参数。
例如,一个需要查询天气的 Agent 可能会输出如下内容:
1 | Thought: I need to check the current weather for New York. |
另一种方法是使用 Code Agent(代码代理)。其核心思想是:不再输出简单的 JSON 对象,而是由 Code Agent 生成一个可执行的代码块 —— 通常使用像 Python 这样高级的编程语言。
相比于类似 JSON 的片段,使用代码来编写 Action 具有以下优势:
- 可组合性(Composability):你能在 JSON 中嵌套 Action 吗?能像定义 Python 函数那样预定义一组 JSON 操作并重复调用吗?代码可以。
- 对象管理能力(Object management):如果你用 JSON 来执行
generate_image,你该如何存储它的输出? - 通用性(Generality):代码天生就是为了表达计算机可以做的几乎任何事情。
- 训练数据中的表示能力(Representation in LLM training data):大量高质量的代码样例早已被用于训练 LLM,这意味着模型已经对这类任务具备了良好的理解与生成能力!
Observation
**Observation(观察)*是指 Agent 感知其行为后果的方式。
它们为 Agent 的思考过程提供了关键信息,并指引其未来的行动。观察可以看作是来自环境的*反馈信号,无论是 API 返回的数据、错误信息,还是系统日志,都会影响下一轮的思考循环。
在观察阶段,Agent 会:
- 收集反馈:接收执行操作后的数据或确认(无论是成功还是失败);
- 追加结果:将新获得的信息整合进当前上下文,相当于更新自身“记忆”;
- 调整策略:利用更新后的上下文优化下一步的思考和行动。
这种反馈的循环式融入机制确保了 Agent 始终动态对齐其目标,并能根据真实世界的结果不断学习与调整。
在执行某个 Action 后,Agent 框架通常依照以下步骤进行:
- 解析 Action:识别要调用的函数及其参数;
- 执行该 Action;
- 将执行结果追加为 Observation(观察)。