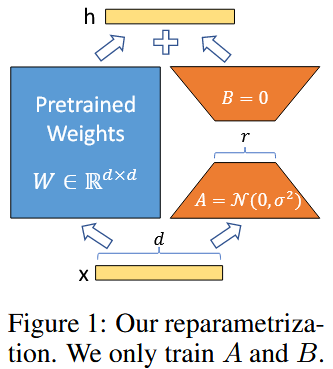
Many applications in natural language processing rely on adapting one large-scale, pre-trained language model to multiple downstream applications. Such adaptation is usually done via fine-tuning, which updates all the parameters of the pre-trained model. The major downside of fine-tuning is that the new model contains as many parameters as in the original model.
Many sought to mitigate this by adapting only some parameters or learning external modules for new tasks. This way, we only need to store and load a small number of task-specific parameters in addition to the pre-trained model for each task, greatly boosting the operational efficiency when deployed. However, existing techniques often introduce inference latency by extending model depth or reduce the model’s usable sequence length.
We take inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension. We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”, leading to our proposed Low-Rank Adaptation (LoRA) approach.
LORA 的做法并不局限于大模型领域,它的作用是在 linear 层上,理论上有 linear 层就可以用。
# lora 相关参数的基类 classLoRALayer(): def__init__( self, r: int, lora_alpha: int, lora_dropout: float, merge_weights: bool, ): self.r = r self.lora_alpha = lora_alpha # Optional dropout if lora_dropout > 0.: self.lora_dropout = nn.Dropout(p=lora_dropout) else: self.lora_dropout = lambda x: x # Mark the weight as unmerged self.merged = False self.merge_weights = merge_weights # 继承 linear 类 classLinear(nn.Linear, LoRALayer): # LoRA implemented in a dense layer def__init__( self, in_features: int, out_features: int, r: int = 0, lora_alpha: int = 1, lora_dropout: float = 0., fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out) merge_weights: bool = True, **kwargs ): nn.Linear.__init__(self, in_features, out_features, **kwargs) LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out # Actual trainable parameters 初始化时额外创建两个矩阵 B A if r > 0: self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features))) self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r))) self.scaling = self.lora_alpha / self.r # Freezing the pre-trained weight matrix self.weight.requires_grad = False self.reset_parameters() if fan_in_fan_out: self.weight.data = self.weight.data.transpose(0, 1)
# lora 矩阵的初始化 defreset_parameters(self): nn.Linear.reset_parameters(self) ifhasattr(self, 'lora_A'): # initialize B the same way as the default for nn.Linear and A to zero # this is different than what is described in the paper but should not affect performance nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5)) nn.init.zeros_(self.lora_B) # 设置是否训练 lora,不训练时是预训练阶段,训练就是微调阶段,这里只设置状态变量 merged 和权重 deftrain(self, mode: bool = True): defT(w): return w.transpose(0, 1) ifself.fan_in_fan_out else w nn.Linear.train(self, mode) if mode: ifself.merge_weights andself.merged: # Make sure that the weights are not merged ifself.r > 0: self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling self.merged = False else: ifself.merge_weights andnotself.merged: # Merge the weights and mark it ifself.r > 0: self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling self.merged = True
# 当 merged 时,额外加上 lora 的结果,否则只用 linear 的结果 defforward(self, x: torch.Tensor): defT(w): return w.transpose(0, 1) ifself.fan_in_fan_out else w ifself.r > 0andnotself.merged: result = F.linear(x, T(self.weight), bias=self.bias) result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling return result else: return F.linear(x, T(self.weight), bias=self.bias)
template ={ "description": "Legacy template, used by Original Alpaca repository.", "prompt_input": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:", "prompt_no_input": "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:", "response_split": "### Response:" }