
Alpaca 源码分析
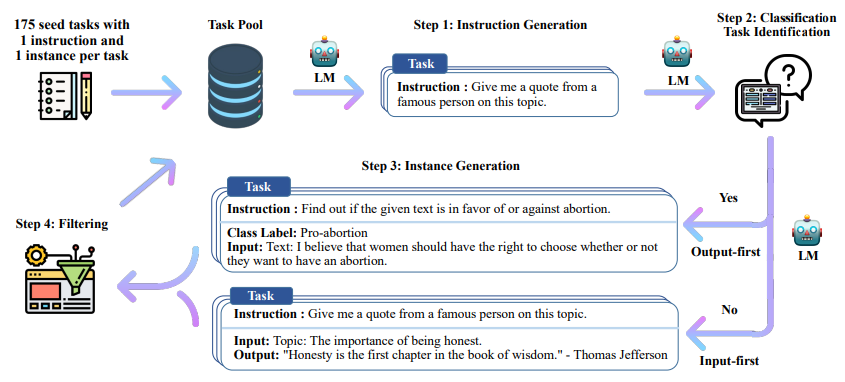
Self-Instruct 过程是一种迭代自举算法,它从一组手动编写的指令种子集开始,并用它们来提示语言模型生成新的指令以及相应的输入 - 输出实例。然后对这些生成结果进行过滤以去除低质量或相似的实例,所得数据被添加回任务池中。这个过程可以重复多次,从而产生大量的指令数据集合,可用于微调语言模型以更有效地遵循指令。
alpaca 源码地址: https://github.com/tatsu-lab/stanford_alpaca.git
加载模型
1 | model_name_or_path = '../DataCollection/officials/Qwen2.5-1.5b-Instruct' |
注意需要检查tokenizer.pad_token_id,因为在padding时会用到,其他eos之类的不需要检查。
加载json数据
数据原始格式(假设只有两条微调数据)
1 | [ |
每条都是三元组的形式, 数据字段如下:
instruction(指令):描述模型应执行的任务。52000 条指令中的每一条都是唯一的。
input(输入):任务的可选上下文或输入。大约 40% 的示例有输入。(可选的,因为可有可无,所以需要有两种拼接格式)
output(输出):由 text-davinci-003 生成的指令答案。
1 | def _make_r_io_base(f, mode: str): |
输出
1 | 52002 |
拼接dict数据
1 | PROMPT_DICT = { |
1 | pprint(list_data_dict[0]) |
输出
1 | {'input': '', |
注意并不是直接拼接,而是加入了类似system prompt的前置说明,和指令和生成内容的标识符
预处理数据 tokenize
这一节将句子转换为input_ids和label。注意label只有output部分内容是有有效的,其他无效(包括prompt)。在指令微调(Instruction Tuning)中,通常我们仅设置输出部分的 label(即目标序列)是有效的,而忽略输入部分的 label,这是因为以下原因:
在指令微调(Instruction Tuning)中,通常我们仅设置输出部分的 label(即目标序列)是有效的,而忽略输入部分的 label,这是因为以下原因:
1.输入部分是提示(Prompt),无需计算损失
- 指令微调的核心目标是让模型学会在特定提示(Prompt)下生成符合预期的输出。
- 输入部分(指令和上下文)作为条件提供给模型,用于引导模型生成合适的输出。它本身并不需要预测,因此不应对输入部分计算损失或更新权重。
- 如果对输入部分计算损失,模型可能会尝试“记住”输入,而非专注于学习如何生成正确的输出。
2.语言模型的自回归性质
- Transformer 模型(如 GPT 或 LLaMA)的自回归训练目标是最大化下一个 token 的概率。
- 在微调时,输入部分(Prompt)已经是已知的条件,因此模型的主要任务是基于输入生成正确的输出(即目标文本)。对输入部分计算损失没有意义。
3.对齐训练目标
- 微调的训练目标是让模型在给定提示下生成期望的响应。这种训练目标的优化重点是输出部分的预测。
- 通过忽略输入部分的 label,只优化输出部分的生成,能够更准确地对齐训练目标与实际使用目标。
4.对生成任务的意义
- 指令微调模型通常应用于生成任务(如回答问题、对话、翻译等),其重点是生成的内容,而非输入的内容。
- 忽略输入部分的 label 有助于模型专注于如何生成符合上下文和指令的内容,而不是浪费资源在回归输入上。
5.实际效果
- 如果强行对输入部分计算损失,训练后的模型可能会出现以下问题:生成的输出可能更倾向于复制输入内容,而非理解指令后生成有意义的回答。对生成任务的泛化能力较弱,因为输入部分的损失干扰了输出部分的优化。
6.避免梯度干扰
- 如果对输入部分和输出部分同时计算损失,模型可能会受到梯度干扰:输入部分的 token 会被错误地视为目标,导致模型尝试“预测”已知的输入内容。
- 这会对生成任务的优化目标造成负面影响,降低模型在输出部分生成正确内容的能力。
总结:在指令微调时,只对输出部分计算 label 是为了:
- 专注于优化生成目标。
- 避免梯度干扰。
- 提高模型对指令生成任务的泛化能力。
1 | IGNORE_INDEX = -100 |
1 | for k in data_dict.keys(): |
1 | 52002 |
封装为dataset
1 | class SupervisedDataset(Dataset): |
这时候每个句子还是单独的tensor,由于transformer中的已有DataCollator一般不会接受label(会报错,一般只接受input_ids和attention_mask),所以需要单独写一个DataCollator
padding DataCollator
1 |
|
注意DataCollator的输入是list[dict[str, tensor]],不要直接把dataset的元素以dataset[a:b]的格式输入给DataCollator。
train
1 | train_dataset = SupervisedDataset(**data_dict) |
1 | training_args = TrainingArguments(output_dir='./output', |
修改Alpaca源码
改进文件读取和预处理
1.huggingface的dataset读取
1 | from datasets import load_dataset |
输出
1 | DatasetDict({ |
2.dataset的批量预处理
1 | IGNORE_INDEX = -100 |
输出
1 | Dataset({ |
半精度训练
1.模型加载,加载时设置torch_dtype
1 | model_name_or_path = '../DataCollection/officials/Llama-2-7b' |
必须要在加载前设置,不然训练时还会以默认的fp32加载入cuda,最终还会OOM
2.训练参数,增加bf16=True
1 | training_args = TrainingArguments(output_dir='./output', |