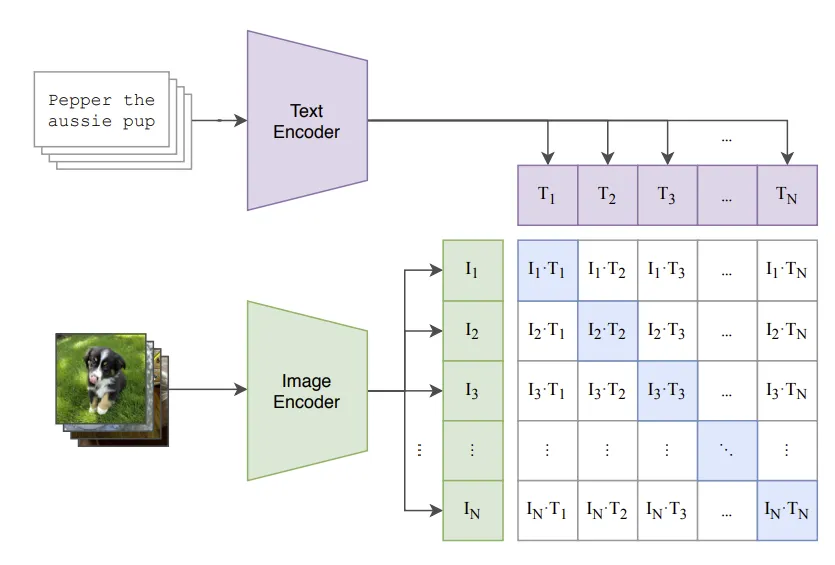
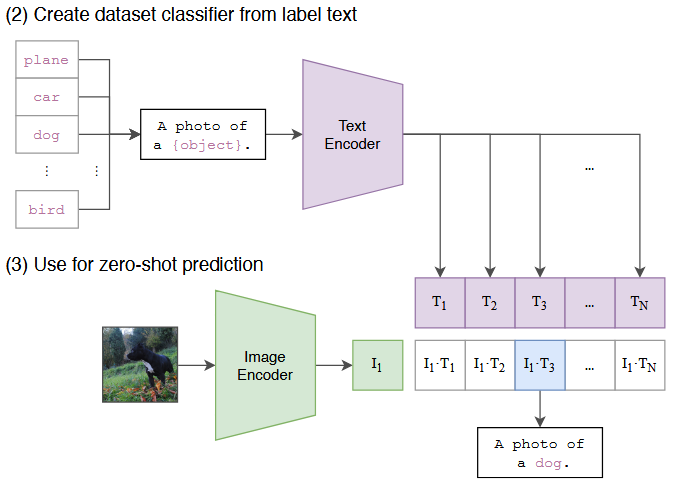
CLIP - Contrastive Language-Image Pre-training
Learning Transferable Visual Models From Natural Language Supervision paper:https://arxiv.org/abs/2103.00020
OpenAI 推出了 CLIP,即 对比式语言-图像预训练(Contrastive Language-Image Pre-training)。简而言之,该模型学习的是整句话与其描述的图像之间的关系;也就是说,当模型训练完成后,给定一段输入文本,它能够检索出与该文本最相关的图像。这里的一个关键点是,它的训练是基于完整句子,而不是单一的类别(例如“汽车”、“狗”等)。其核心直觉在于,使用完整句子进行训练可以让模型学到更多信息,从而在图像与文本之间发现潜在的模式。
CLIP jointly trains an image encoder and a text encoder to predict the correct pairings of a batch of (image, text) training examples.
说直白点,就是让 image embedding 和 (与 image 配对的text)的 text embedding 相似度高,与其他不匹配的 text 的 text embedding 相似度低。我们训练对象是 image encoder 和 text encoder,更准确点,我们会用预训练模型作为 encoder,然后在其后面加入 projection head 来将源模态的 embedding 转为为 unified embedding (统一的模态),encoder 预训练,仅微调,projection head 从头开始训练,这也解决了 embedding 维度不一样的问题。
At test time the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the target dataset’s classes.
在实际 zero-shot 分类时,取各个类别转换为 text,经过 text encoder 转换为各个类别的 text embedding。同时,需要分类的 image 经过 image encoder 转换为 image embedding,计算 image embedding 和 text embedding 之前的相似度,softmax 后最高者对应的类别就是分类结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import osimport cv2import numpy as npimport pandas as pdfrom tqdm import tqdmimport albumentations as Aimport timmimport torchfrom torch import nnfrom transformers import AutoModel, AutoTokenizer, DistilBertConfigimport osos.environ["TOKENIZERS_PARALLELISM" ] = "false"
加载 image - caption Flicker-8k 数据地址:https://www.kaggle.com/datasets/adityajn105/flickr8k
Flicker-8k 将配对数据保存为 txt,此处读取为 dataframe
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 image_path = "./Flicker-8k/Images" captions_path = "./Flicker-8k/captions.txt" train_ratio = 0.5 batch_size = 32 num_workers = 4 size = 224 dataframe = pd.read_csv(captions_path) print ('num of data:' , len (dataframe))dataframe = dataframe.sample(frac=1 , random_state=42 ).reset_index(drop=True ) train_size = int (len (dataframe) * train_ratio) train_dataframe = dataframe[:train_size] test_dataframe = dataframe[train_size:]
image
caption
0
1000268201_693b08cb0e.jpg
A child in a pink dress is climbing up a set of stairs in an entry way .
1
1000268201_693b08cb0e.jpg
A girl going into a wooden building .
2
1000268201_693b08cb0e.jpg
A little girl climbing into a wooden playhouse .
3
1000268201_693b08cb0e.jpg
A little girl climbing the stairs to her playhouse .
4
1000268201_693b08cb0e.jpg
A little girl in a pink dress going into a wooden cabin .
5
1001773457_577c3a7d70.jpg
A black dog and a spotted dog are fighting
6
1001773457_577c3a7d70.jpg
A black dog and a tri-colored dog playing with each other on the road .
7
1001773457_577c3a7d70.jpg
A black dog and a white dog with brown spots are staring at each other in the street .
8
1001773457_577c3a7d70.jpg
Two dogs of different breeds looking at each other on the road .
9
1001773457_577c3a7d70.jpg
Two dogs on pavement moving toward each other .
每个图片都有 5 个 caption 来描述其内容。
1 2 tokenizer = AutoTokenizer.from_pretrained("/home/guest/others/data_collection/distilbert-base-uncased" ) print (tokenizer("hello" ))
数据集设置很简单,相比于有监督学习的 x 和 y,对比学习是正样本和负样本。以上每一行的 image 和 caption 就是正样本,而负样本是同一 batch 的其他 caption。
虽然严格意义上,我们可能遇到同一 batch 里的两个 image 是一样,但其对应 caption 是语义上类似,但不严格相同的。这种情况下还是会被视为负样本,但考虑到这样的情况很少出现,即很小概率正样本被当作负样本处理,所以整体训练上是没毛病的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 def get_transforms (mode="train" ): if mode == "train" : return A.Compose([ A.Resize(size, size), A.Normalize(max_pixel_value=255.0 ), ]) else : return A.Compose([ A.Resize(size, size), A.Normalize(max_pixel_value=255.0 ), ]) class CLIPDataset (torch.utils.data.Dataset): def __init__ (self, image_filenames, captions, tokenizer, transforms ): """ image_filenames and cpations must have the same length; so, if there are multiple captions for each image, the image_filenames must have repetitive file names """ self .image_filenames = image_filenames self .captions = list (captions) self .encoded_captions = tokenizer( list (captions), padding=True , truncation=True , max_length=200 ) self .transforms = transforms def __getitem__ (self, idx ): item = { key: torch.tensor(values[idx]) for key, values in self .encoded_captions.items() } image = cv2.imread(f"{image_path} /{self.image_filenames[idx]} " ) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = self .transforms(image=image)['image' ] item['image' ] = torch.tensor(image).permute(2 , 0 , 1 ).float () item['caption' ] = self .captions[idx] return item def __len__ (self ): return len (self .captions) def build_loaders (dataframe, tokenizer, mode, batch_size=32 , num_workers=4 ): transforms = get_transforms(mode=mode) dataset = CLIPDataset( dataframe["image" ].values, dataframe["caption" ].values, tokenizer=tokenizer, transforms=transforms, ) dataloader = torch.utils.data.DataLoader( dataset, batch_size=batch_size, num_workers=num_workers, shuffle=True if mode == "train" else False , ) return dataloader train_loader = build_loaders(train_dataframe, tokenizer, mode="train" , batch_size=batch_size) valid_loader = build_loaders(train_dataframe, tokenizer, mode="valid" , batch_size=batch_size)
1 2 3 a_batch = next (iter (train_loader)) for k, v in a_batch.items(): print (f"key name: {k} , value data type: {type (v)} , value shape: {v.shape if isinstance (v, torch.Tensor) else len (v)} " )
1 2 3 4 key name: input_ids, value data type: <class 'torch.Tensor '> key name: attention_ mask, value data type: <class 'torch.Tensor '> key name: image, value data type: <class 'torch.Tensor '> key name: caption, value data type: <class 'list '>
模型
image encoder 用 resnet 或者 vit,forward不变,返回图片 embedding
text encoder 用 bert 变体 distilbert,foward返回 CLS token 位置的 embedding
两个 projection head 分别把 image embedding 和 text embedding 转换为统一的 embedding
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 class ImageEncoder (nn.Module): """ Encode images to a fixed size vector """ def __init__ ( self, model_name='resnet50' , pretrained=True , trainable=True , pretrained_cfg_overlay=None ): super ().__init__() self .model = timm.create_model( model_name, pretrained, num_classes=0 , global_pool="avg" , pretrained_cfg_overlay=pretrained_cfg_overlay ) for p in self .model.parameters(): p.requires_grad = trainable def forward (self, x ): return self .model(x) class TextEncoder (nn.Module): def __init__ (self, model_name="distilbert-base-uncased" , pretrained=True , trainable=True ): super ().__init__() if pretrained: self .model = AutoModel.from_pretrained(model_name) else : self .model = AutoModel(config=DistilBertConfig()) for p in self .model.parameters(): p.requires_grad = trainable self .target_token_idx = 0 def forward (self, input_ids, attention_mask ): output = self .model(input_ids=input_ids, attention_mask=attention_mask) last_hidden_state = output.last_hidden_state return last_hidden_state[:, self .target_token_idx, :] class ProjectionHead (nn.Module): def __init__ ( self, embedding_dim, projection_dim=256 , dropout=0.1 ): super ().__init__() self .projection = nn.Linear(embedding_dim, projection_dim) self .gelu = nn.GELU() self .fc = nn.Linear(projection_dim, projection_dim) self .dropout = nn.Dropout(dropout) self .layer_norm = nn.LayerNorm(projection_dim) def forward (self, x ): projected = self .projection(x) x = self .gelu(projected) x = self .fc(x) x = self .dropout(x) x = x + projected x = self .layer_norm(x) return x class CLIPModel (nn.Module): def __init__ ( self, image_encoder, text_encoder, image_embedding=2048 , text_embedding=768 , temperature=1.0 , ): super ().__init__() self .image_encoder = image_encoder self .text_encoder = text_encoder self .image_projection = ProjectionHead(embedding_dim=image_embedding) self .text_projection = ProjectionHead(embedding_dim=text_embedding) self .temperature = temperature def forward (self, images:torch.tensor, input_ids:torch.tensor, attention_masks:torch.tensor ): image_features = self .image_encoder(images) text_features = self .text_encoder( input_ids=input_ids, attention_mask=attention_masks ) image_embeddings = self .image_projection(image_features) text_embeddings = self .text_projection(text_features) logits = (text_embeddings @ image_embeddings.T) / self .temperature return logits, image_embeddings, text_embeddings
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 image_encoder = ImageEncoder( model_name='resnet50' , pretrained_cfg_overlay=dict (file='/home/guest/others/xp/clip/timm-resnet50/pytorch_model.bin' ), ) text_encoder = TextEncoder( model_name="/home/guest/others/data_collection/distilbert-base-uncased" ) model = CLIPModel( image_encoder=image_encoder, text_encoder=text_encoder, image_embedding=2048 , text_embedding=768 , temperature=1.0 , )
训练函数 loss 有两种写法
CLIP 原文用的就是对角矩阵为 label 的情况,只要分别在 dim0 和 dim1 与 arange(n) 序列作交叉熵计算就行。原文就是这样实现的,以下是论文中的伪代码。
Given a batch of N (image, text) pairs, CLIP is trained to predict which of the N × N possible (image, text) pairings across a batch actually occurred. To do this, CLIP learns a with high pointwise mutual information as well as the names of all Wikipedia articles above a certain search volume. Finally all WordNet synsets not already in the query list are added. multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N^2 − N incorrect pairings.
1 2 3 4 5 6 batch_size = image_embeddings.shape[0 ] labels = torch.arange(batch_size).to(device) texts_loss = self .criterion(logits, labels) images_loss = self .criterion(logits.T, labels) loss = (images_loss + texts_loss) / 2.0
还有一种是以 image-image 和 text-text 相似度为 ground truth,对角线肯定相似度很高,另外部分非对角线数据也会根据其实际 image-image 和 text-text 的相似度。这种方式我感觉可以弥补正样本被视为负样本的情况。
1 2 3 4 5 6 7 8 images_similarity = image_embeddings @ image_embeddings.T texts_similarity = text_embeddings @ text_embeddings.T targets = F.softmax( (images_similarity + texts_similarity) / 2 * self .temperature, dim=-1 ) texts_loss = nn.CrossEntropyLoss()(logits, targets) images_loss = nn.CrossEntropyLoss()(logits.T, targets.T) loss = (images_loss + texts_loss) / 2.0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 def train_batch (model, optimizer, batch, device ): optimizer.zero_grad() criterion = nn.CrossEntropyLoss() images = batch["image" ].to(device) input_ids = batch["input_ids" ].to(device) attention_masks = batch["attention_mask" ].to(device) logits, image_embeddings, text_embeddings = model( images=images, input_ids=input_ids, attention_masks=attention_masks ) batch_size = image_embeddings.shape[0 ] labels = torch.arange(batch_size).to(device) texts_loss = criterion(logits, labels) images_loss = criterion(logits.T, labels) loss = (images_loss + texts_loss) / 2.0 loss.backward() optimizer.step() return loss.item() def train_epoch (model, optimizer, dataloader, device ): model.train() losses = [] for batch in tqdm(dataloader): batch_loss = train_batch(model, optimizer, batch, device) losses.append(batch_loss) ave_loss = np.mean(losses) return ave_loss def test_batch (model, batch, device ): images = batch["image" ].to(device) input_ids = batch["input_ids" ].to(device) attention_masks = batch["attention_mask" ].to(device) logits, image_embeddings, text_embeddings = model( images=images, input_ids=input_ids, attention_masks=attention_masks ) gt = torch.arange(logits.size(0 ), device=logits.device) pred = torch.argmax(logits, dim=1 ) correct = (pred == gt).sum ().item() return correct / logits.size(0 ) def test_epoch (model, dataloader, device ): model.eval () accs = [] with torch.no_grad(): for batch in tqdm(dataloader): batch_acc = test_batch(model, batch, device) accs.append(batch_acc) ave_acc = np.mean(accs) return ave_acc
训练流程 这里考虑到 image encoder 和 text encoder 都是已经预训练的,而 projection head 是从 scatch 开始训的,所以最好设置 encoder 的学习率较低, projection head 的学习率为正常值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 n_epochs = 20 device = torch.device("cuda:1" ) model = model.to(device) optimizer = torch.optim.AdamW([ {"params" : model.image_encoder.parameters(), "lr" : 1e-5 }, {"params" : model.text_encoder.parameters(), "lr" : 1e-5 }, {"params" : model.image_projection.parameters(), "lr" : 1e-3 }, {"params" : model.text_projection.parameters(), "lr" : 1e-3 }, ]) lr_scheduler = torch.optim.lr_scheduler.StepLR( optimizer, step_size=5 , gamma=0.5 , ) for epoch in range (20 ): print (f"Epoch: {epoch + 1 } " ) print (f'Learning Rate: {lr_scheduler.get_last_lr()[0 ]} ' ) train_loss = train_epoch(model, optimizer, train_loader, device) print (f"Train Loss: {train_loss:.4 f} " ) test_acc = test_epoch(model, valid_loader, device) print (f"Test Accuracy: {test_acc:.4 f} " ) lr_scheduler.step()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Epoch: 1 Learning Rate: 1e-05 100%|██████████| 633/633 [02:00<00:00, 5.27it/s] Train Loss: 2.2545 100%|██████████| 633/633 [00:50<00:00, 12.64it/s] Test Accuracy: 0.7001 Epoch: 2 Learning Rate: 1e-05 100%|██████████| 633/633 [02:07<00:00, 4.98it/s] Train Loss: 0.7770 100%|██████████| 633/633 [01:08<00:00, 9.23it/s] Test Accuracy: 0.8489 Epoch: 3 Learning Rate: 1e-05 100%|██████████| 633/633 [02:18<00:00, 4.58it/s] Train Loss: 0.4705 100%|██████████| 633/633 [01:04<00:00, 9.77it/s] Test Accuracy: 0.9080 Epoch: 4 Learning Rate: 1e-05 100%|██████████| 633/633 [01:53<00:00, 5.56it/s] Train Loss: 0.3176 100%|██████████| 633/633 [00:50<00:00, 12.51it/s] Test Accuracy: 0.9228 Epoch: 5 Learning Rate: 1e-05 100%|██████████| 633/633 [01:57<00:00, 5.40it/s] Train Loss: 0.2462 100%|██████████| 633/633 [00:51<00:00, 12.20it/s] Test Accuracy: 0.9343