
FSDP - Fully Sharded Data Parallel
FSDP 是 DDP 的一种改进,它晚于 deepspeed 出现,它其实就是 zero-3: 把权重、梯度、优化器全部 sharding 存储。理解起来不难,结合下 NCCL 通信就可以知道他干什么和怎么实现的。记住,FSDP的两个关键点,sharding 和 data parallel。
sharding
在深度学习中,shard(分片)指的是把一个整体的数据结构或模型参数拆成多个部分,分别分布到不同设备或进程中处理或存储。通俗点,Sharding 就是“切块+分发”。
Sharding 的思想就是万物都可以分裂开,只要用的时候再复原,而且用完继续分裂开。这里的分裂不是常规意义上的分裂,更类似与分布式存储,每个节点都存储部分内容。FSDP 的前任是 DDP,DDP 的前提条件是每个 gpu 上都有一个模型副本,但随着模型不断变大,模型很难在单张 gpu 上部署,而且所有 gpu 都保存了大量重复的参数,也不够有效。

模型并行是一个解决方法:
- 将整个模型按层划分为多个连续的阶段(stage),每个阶段由一个设备负责计算。
- 在每个训练迭代开始时,第一个设备获取一个 batch 的输入数据,并执行前向计算。
- 第一个设备将计算出的中间激活值(activations)传递给第二个阶段的设备。
- 第二个设备接收到激活值后,基于这个输入继续执行前向计算,并将结果传递给下一个阶段,如此类推。
- 直到最后一个阶段完成前向计算,得到最终的输出。
- 基于输出,计算损失函数,并执行反向传播。
- 每个阶段在反向传播时,计算本阶段所需的梯度,并将上游梯度传递给前一个阶段。
- 所有阶段计算完成后,将各自的梯度汇总,更新对应的模型参数。
- 将更新后的模型参数分发到对应的设备,准备进行下一个 batch 的训练迭代。
但他还是以 layer 层面切分模型的,现在如果有超大的 layer,必然存在放不了一个超大的 layer 或者剩下的空间不足以放下一个 layer。
虽然模型并行和 sharding 都是只在多 gpu 上保留一份模型参数,但 sharding 直接分裂开 tensor,粒度更细,使得其更灵活。
Shard parameters, gradients, and optimizer states across all data-parallel processes
- P: Parameters
- G: Gradients
- OS: Optimizer states
这是 deepspeed 介绍他们三种模式的图片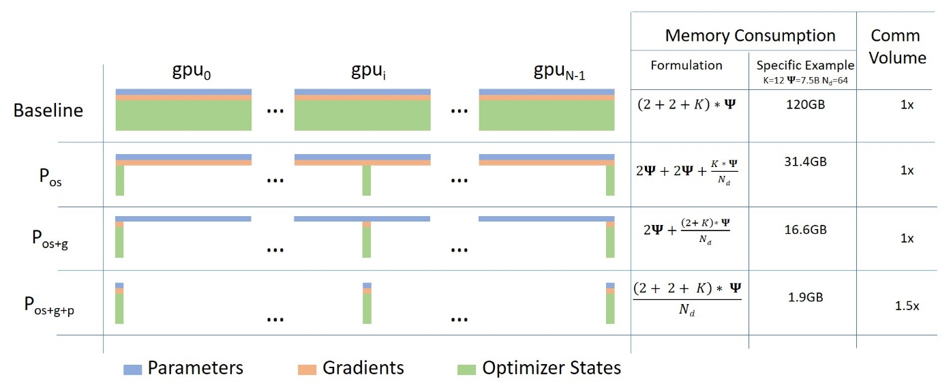
随着我们从 Optimizer 到 Gradients 到 Parameters 不断 sharding,每个 gpu 上的显存占用直线降低,而通讯压力仅有极小的成本上升。
sharding 的重要基础就是 NCCL 的通信机制,例如以下的通信方式:
- all-gather,
- all-reduce,
- broadcast,
- reduce,
- reduce-scatter
- as well as point-to-point send and receive
The NVIDIA Collective Communication Library (NCCL) implements multi-GPU and multi-node communication primitives optimized for NVIDIA GPUs and Networking.
在 DDP 中我们就用了 all-reduce 的概念,即每个 gpu 上都计算了分配给它的 mini batch 的梯度,为了让所有卡上都维持相同的模型,or梯度更新都一致,我们用 all-reduce 让所有 gpu 上的梯度都获得了所有 gpu 上的梯度。FSDP 在此基础上,让 FWD 和 BWD 过程都利用 all-reduce 实现了参数随用随 gather,用完即丢的效果。
sharding 示例
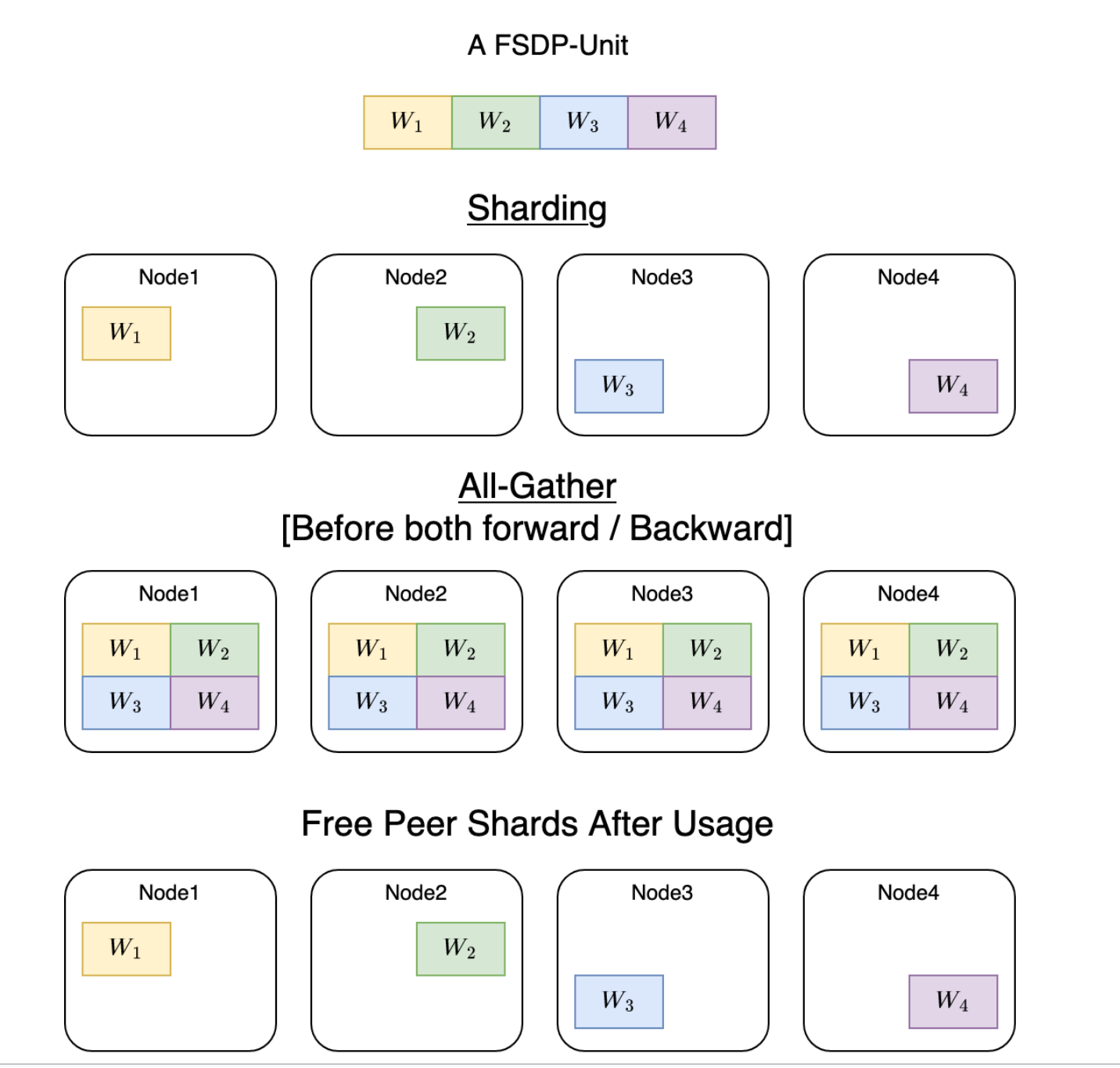
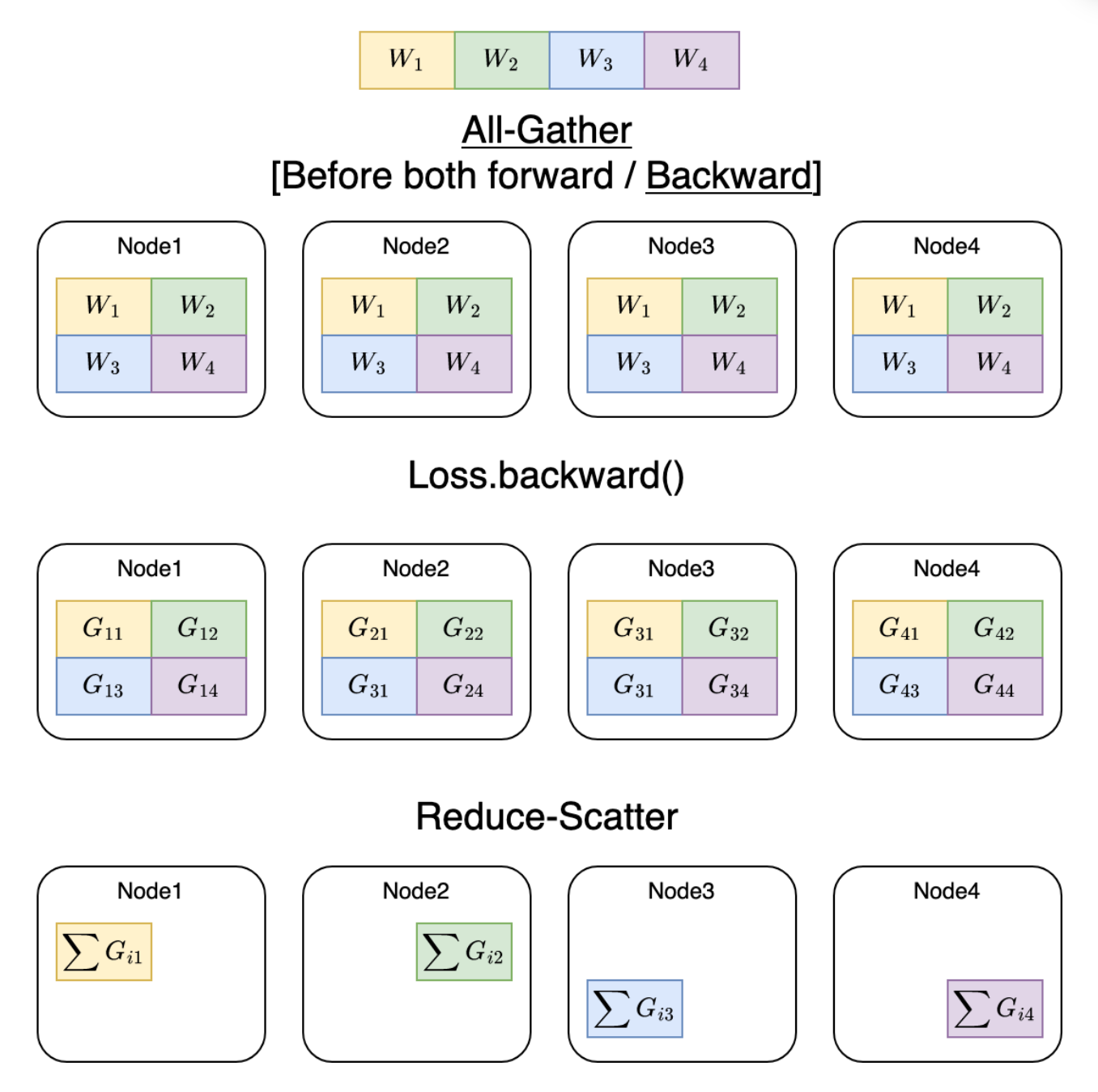
这里以一个 Linear 层为例,现在共有 4 个节点,我们把 linear 层平均的分散到每个 gpu 上,每个 gpu 只有一部分,不足以直接计算,现在 FWD 和 BWD 时,每个节点以 all-gather 的形式将所有节点上的 shard 收集为完整的 linear 层,这样每个节点都可以基于它自己的数据计算出输出,现在这个输出可以转到下一个层的计算,也是同样的 all-gather,而已经用的层,后续不再需要,因此直接释放,还是只保留原本的 shard。
FSDP 并不会对数据进行切分,因为它还是属于 data parallel 的范畴,即每个节点上运行部分数据,一个节点上的数据就交给这个节点计算,因此数据不会切分。
FSDP 本质上仍是一种数据并行(DP)策略,目标是解决单卡放不下完整模型的问题,同时保留传统 DDP 的易用性与训练逻辑。
不同于模型并行(MP)或流水线并行(PP)那种“切分计算”的思想,FSDP 并不切算子,而是切分参数存储(shard weight storage),从而在所有 GPU 上共同维护一个被 shard 化的模型。
!!! 注意,FSDP 不涉及张量并行或者模型并行的概念,它只用 sharding 来存储参数,用 gather 来随时收集分散的参数,此外和正常计算一样,计算方式上没有任何改变。
toy model
以下是一个 手动 sharding 和 gather shard 的 toy model。
1 | import os |
1 | # CUDA_VISIBLE_DEVICES=1,2 python demo.py |
FSDP
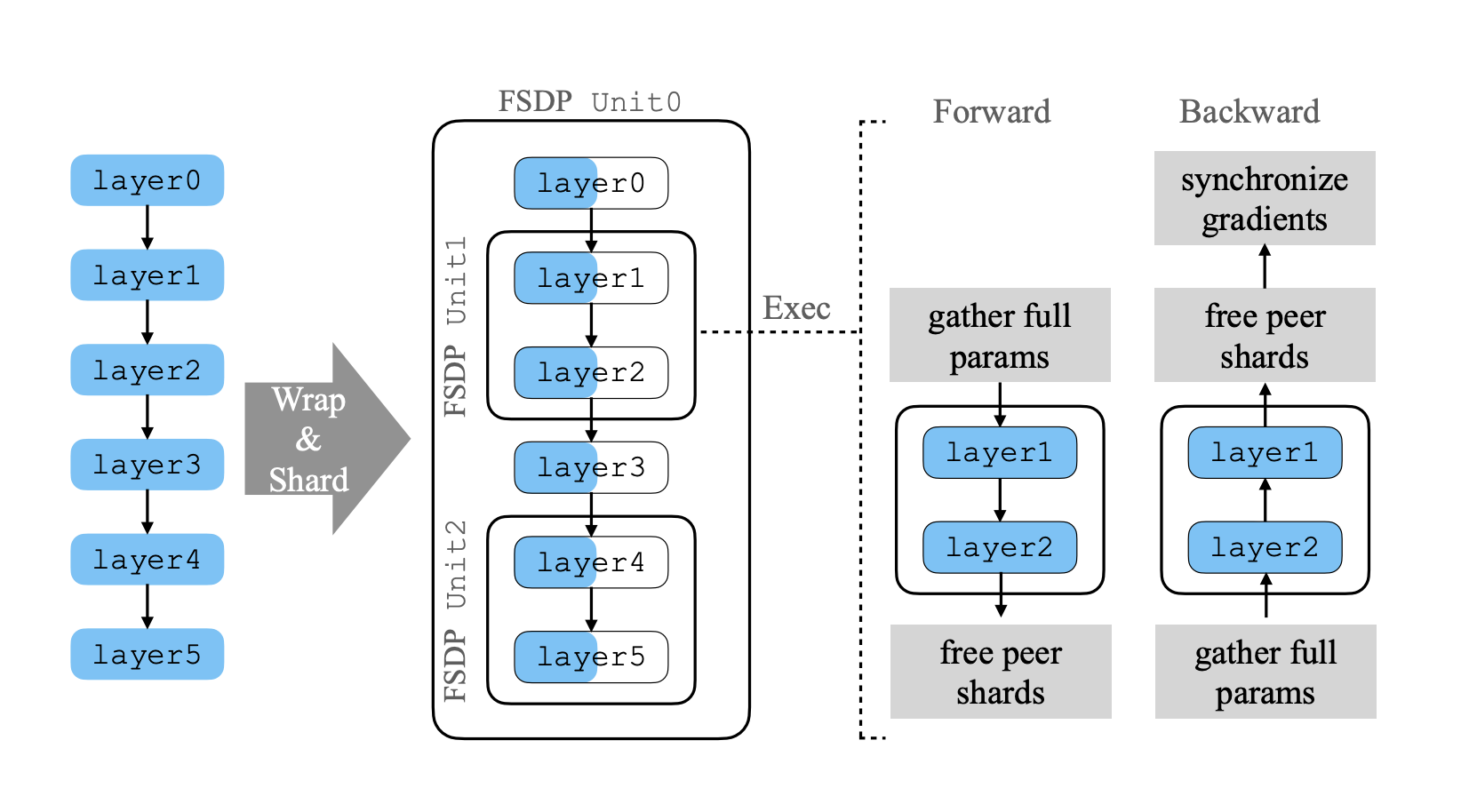
以图为例,重新分散模型:
- unit 0: [layer 0, layer 3]
- unit 1: [layer 1, layer 2]
- unit 2: [layer 4, layer 5]
这里的 unit 即节点, sharding 本身没有任何顺序或者既定的比例,随便分散即可。每个节点执行 FWD 和 BWD 时都是先 gather 全部参数,计算,在释放非自己的 shard, BWD 同理,最后同步 gradient 。
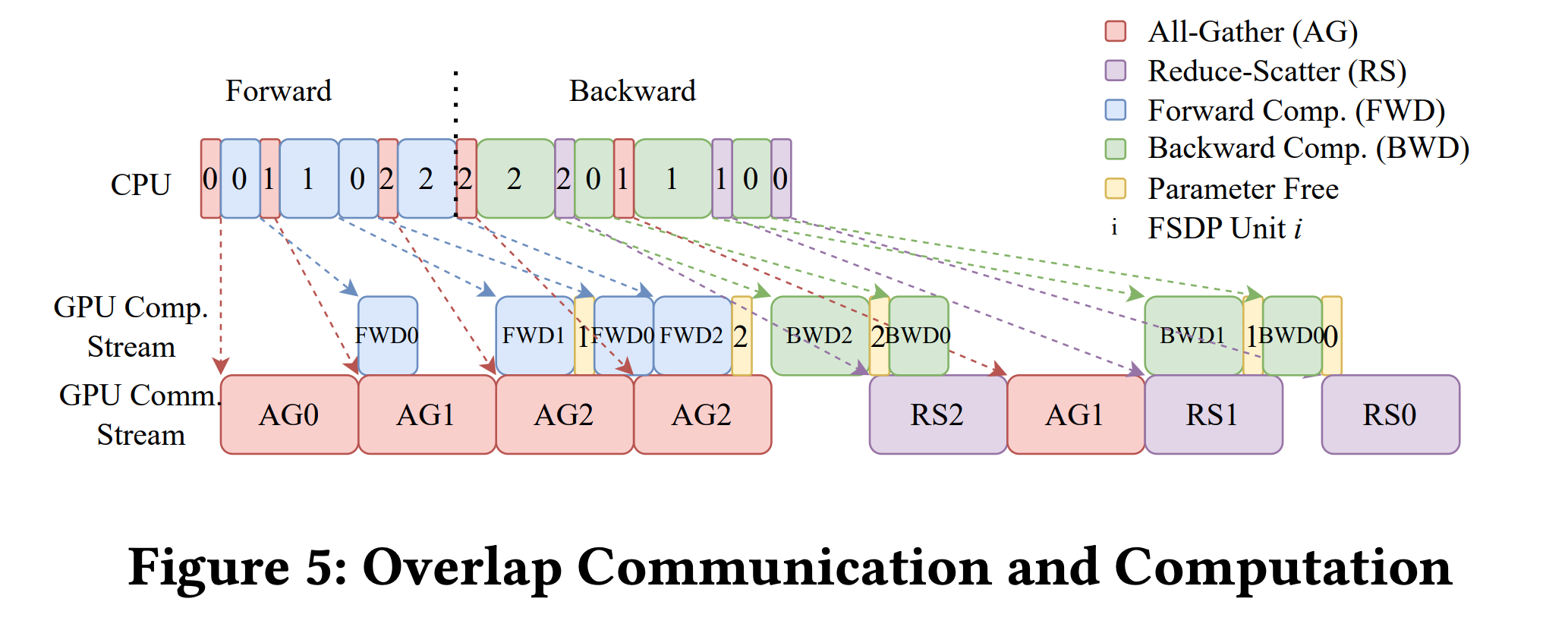
再从计算和通信上看,在进行完 AG0 (all-gather layer 0)时可以同时 FWD0 和 AG1,此时通信和计算就会overlap,但不影响双方。
在 BWD 时也是 all-gather 完了进行 BWD 计算,这里直接进行了 reduce-scatter,因为 FSDP 还是类似 DDP 一样,要维持相同的模型或者梯度更新,这一步直接当前梯度计算完,直接同步。
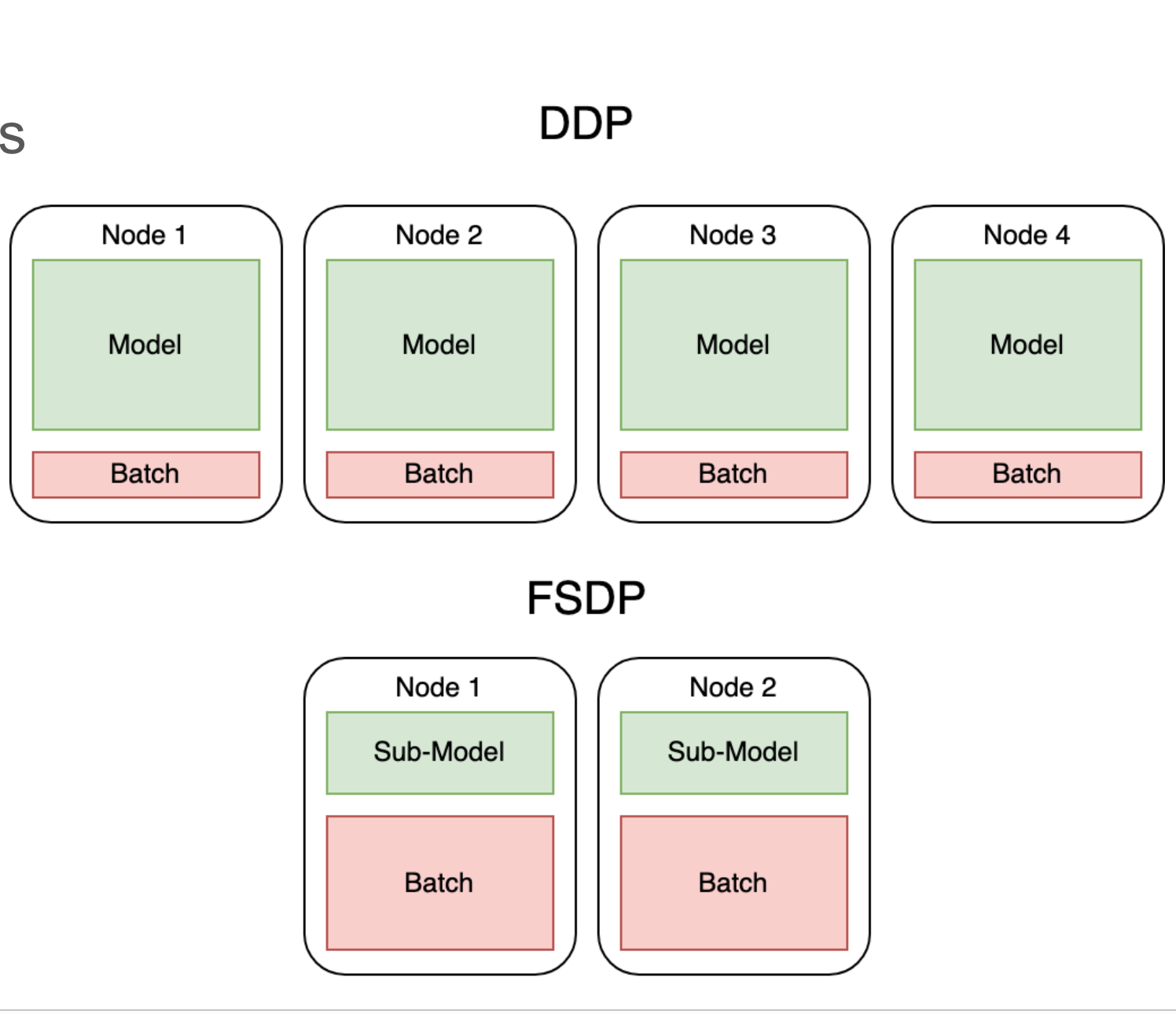
FSDP 和 DDP 的区别还是很明显的,DDP 要在每个节点上保留一个完整的模型副本,模型比较大时就非常吃亏,因为大部分显存都被模型占着。而 FSDP 让所有节点共同存储一个模型,每个模型平摊代价,使得每个节点只需要承担 sub-model 级别的代价,使得可以跑更大的 batch 。
1 | # 大概用 FSDP 包装下模型就可以了,当然也要设置类似 DDP 的参数 |
MNIST FSDP
1 | # Based on: https://github.com/pytorch/examples/blob/master/mnist/main.py |